








Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRISTI - Revista Ibérica de Sistemas e Tecnologias de Informação
versión impresa ISSN 1646-9895
RISTI no.39 Porto oct. 2020
https://doi.org/10.17013/risti.39.114-130
ARTÍCULOS
Creación colaborativa de una arquitectura de referencia para la implementación de plataformas de servicios de datos
Collaborative creation of a reference architecture for the implementation of data service platforms
Edisson Estelio Gutiérrez Jiménez 1, Juan Bernardo Quintero 1, Bell Manrique Losada 1
1 Universidad de Medellín, Carrera 87 No. 30-65, 50026, Medellín, Colombia. eegutierrez@udem.edu.co, juquintero@udem.edu.co, bmanrique@udem.edu.co
RESUMEN
Big Data se refiere a conjuntos de datos cuyo volumen, velocidad y variedad dificultan su captura, gestión y procesamiento mediante tecnologías y herramientas convencionales. Este concepto está generando nuevas necesidades en las organizaciones para permitir la captura, almacenamiento y análisis de datos con estas características y así obtener información relevante para la toma de decisiones. Un reto para las organizaciones es la implementación de una arquitectura que permita cubrir estas necesidades, ya que deben considerar las diferentes tecnologías existentes y deben establecer las políticas para el gobierno de datos que estarán en manos de los usuarios. Una arquitectura de referencia de una plataforma de analítica de datos, que sea capaz de desvincularse de herramientas tecnológicas será una guía que le permitirá a las organizaciones trazar un camino para lograr la gestión de esos datos y así tener herramientas efectivas para la toma de decisiones empresariales.
Palabras-clave: Big data; arquitectura; analítica de datos.
ABSTRACT
Big Data refers to data set whose volume, velocity, and variety make it difficult to capture, manage and process using conventional technologies and tools. This concept is generating new needs in organizations to allow the capture, storage, and analysis of data with these characteristics and thus obtain relevant information for decision-making. A challenge for organizations is the implementation of an architecture that covers these needs, since they must consider the different existing technologies and must establish the policies for data governance that will be available to users. A reference architecture of a data analytics platform that is capable of decoupling from technological tools will be a guide that will allow organizations to define a path to achieve the management of these data and thus have effective tools for make decisions in the company.
Keywords: Big data; architecture; data analytics.
1. Introducción
El descubrimiento de conocimiento y la toma de decisiones a partir de datos de gran volumen, variados, de diferente tipo y con un rápido crecimiento es un reto para las empresas en términos de almacenamiento, administración y procesamiento (Bibri, 2019). El concepto de Big Data es un conjunto de datos cuyo volumen, variedad y velocidad dificultan su captura, gestión y procesamiento mediante tecnologías convencionales (Madden, 2012). Este concepto está generando en las organizaciones la necesidad de recolectar, almacenar, analizar y exhibir datos con estas características para obtener información que ayude a la toma de decisiones y a la proyección en el mercado (Oussous, Benjelloun, Ait Lahcen, & Belfkih, 2018). Unido a esto, los avances tecnológicos de la Cuarta Revolución Industrial y su aplicación en las organizaciones, los cuales buscan la automatización y el intercambio de datos, generarán más volumen de datos y es en este punto donde el Big Data cobra relevancia, ayudando a mejorar el desarrollo de productos y a la innovación de los servicios (Wan, Cai, & Zhou, 2015).
Con el fin de gestionar datos con las características propias del Big Data se han desarrollado diferentes herramientas y arquitecturas tecnológicas, lo que ha generado un desafío para los profesionales de este campo (Mazumder, 2016), ya que ellos deben comprender y seleccionar las herramientas para abordar un problema organizacional relacionado con Big Data y así obtener el conocimiento que se puede extraer de los datos.
Dificultades se presentan en las organizaciones al definir una arquitectura para Big Data, una es que las organizaciones no identifican la forma y las herramientas tecnológicas para gestionar y procesar datos con esas características (Jovanovic, Romero, & Abello, 2017), otra es que las plataformas desarrolladas no facilitan el aumento de la capacidad de trabajo sin comprometer el funcionamiento (Oussous et al., 2018), y la última es el desconocimiento del dominio del problema que se desea atender y de los datos que se procesarán (Zhelev & Rozeva, 2017).
Los servicios de datos se refieren a plataformas para el almacenamiento y distribución de datos con características relacionadas al Big Data (Pollock & Dietrich, 2009), los cuales permiten su diagramación para facilitar el análisis de los datos. La dificultad actual se presenta con la implementación de los servicios de datos, debido a las diferentes tecnologías que existen alrededor de estos servicios sin tener pautas que indiquen cómo será su construcción. Esta misma situación la exponen Jovanovic et al. (2017) al mencionar que la variedad de motores de ejecución para la analítica de datos y la complejidad de las transformaciones son un desafío para las arquitecturas de Big Data y los sistemas de inteligencia de negocio de próxima generación.
Es necesario plantear la definición de una arquitectura de referencia de una plataforma de Big Data, que sea capaz de desvincularse de los detalles técnicos (Blazquez & Domenech, 2018), dicha arquitectura será la base para gestionar datos con características relacionadas al Big Data, no debe estar ligada a herramientas técnicas particulares y debe incluir los posibles tipos de usuario que la pueden utilizar (Zaghloul, Ali-Eldin, & Salem, 2015), los componentes tecnológicos serán determinados por las organizaciones al momento de implementar la arquitectura. En este artículo se presenta una aproximación a una arquitectura de referencia para plataformas de Big Data, la cual incluye dos componentes: los lineamientos que permiten guiar el proceso de implementación y una fase de gobierno de datos, que como lo exponen Khatri & Brown (2010), permitirá tener control sobre los datos que se exponen, definiendo los usuarios que tienen derechos de decisión y se hacen responsables de los activos de datos de la organización.
El resto del artículo se organiza de la siguiente manera: en la primera sección se presenta el contexto inicial de la investigación sustentando el problema planteado y la fundamentación conceptual. En la segunda sección se muestra un análisis del estado del arte mostrando tendencias para solucionar el problema planteado. En la siguiente sección se presenta la arquitectura propuesta para solucionar el problema y se describe en detalle el proceso de implementación y validación. En la sección de hallazgos se muestran los resultados de la experimentación con su respectivo análisis, para finalmente dar las conclusiones y líneas de trabajo futuro.
2. Fundamentación conceptual
En esta sección se describe el marco teórico y referencial que sustenta este trabajo.
2.1. Big data
Big data es un fenómeno caracterizado por un aumento continuo en el volumen, la variedad, la velocidad y la veracidad de los datos que requieren técnicas y tecnologías avanzadas para capturar, almacenar, distribuir, administrar y analizar estos datos (Ebner, Bühnen, & Urbach, 2014). Los cambios rápidos y continuos en el volumen y variedad de los datos requieren de una infraestructura técnica avanzada y de arquitecturas que abarquen estas nuevas características.
2.2. Arquitectura de software
La arquitectura de software se define como la estructura de los componentes de un programa o sistema, sus interrelaciones, y los principios y guías que controlan su diseño y evolución en el tiempo (Kazman, Abowd, Bass, & Webb, 1993). Dentro del desarrollo de software esta área juega un papel importante debido a la continua evolución de sistemas de información y a la creciente evolución de nuevas tecnologías.
Las propiedades particulares del Big Data y el desafío en las organizaciones para gestionar datos con sus características requiere arquitecturas específicas que posean componentes que almacenen, procesen y analicen el volumen y variedad de los datos (Blazquez & Domenech, 2018).
2.3. Arquitecturas para Big data
Con el fin de atender los retos tecnológicos que demanda el Big Data se han definido arquitecturas para atender sus características particulares:
• Arquitecturas intensivas de datos, se componen generalmente de múltiples dispositivos computacionales que pueden resumirse en términos de trabajos, adquiriendo datos de una o más fuentes y produciendo datos en uno o más sumideros. Las fuentes y sumideros de datos pueden ser de varios tipos. Los trabajos dentro de esta arquitectura pueden funcionar por lotes, secuencia o interactivo (Artac et al., 2018).
• Arquitecturas Lambda y Kappa. La arquitectura Lambda combina el procesamiento de datos por lotes y en tiempo real, se enfoca principalmente en la ingestión de datos y presenta dificultades en la implementación y el soporte, debido a que mantener estos procesamientos es complejo; la arquitectura Kappa simplifica la arquitectura Lambda combinando el procesamiento por lotes y en tiempo real en una sola capa, llamada capa de procesamiento, la segunda capa que posee es la de publicación, que se utiliza para consultar resultados (Zhelev & Rozeva, 2017).
• Arquitectura basada en modelos, fue desarrollada para agilizar los procesos de analítica desde la preparación de los datos hasta la visualización. Esta última etapa logra ser más concreta por medio de la automatización de los objetivos que el usuario desea visualizar (Golfarelli & Rizzi, 2019).
• Arquitectura de procesamiento de Big Data, consiste en cuatro etapas: recolección o recopilación, carga, transformación y extracción de datos (Krishnan, 2013).
El potencial del Big Data reside en permitir que las organizaciones aprovechen todos sus datos para comprender, supervisar y planificar eficazmente sus procesos (Bibri, 2019), una de las propuestas para lograr este objetivo es alinear el Big Data y la computación en la nube, debido a las oportunidades que brinda la combinación de estos dos componentes para realizar inteligencia de negocios y análisis de datos (Dabbéchi, Nabli, & Bouzguenda, 2016).
2.4. Inteligencia de negocios
La inteligencia de negocios es un conjunto de aplicaciones, tecnologías y procesos para recopilar, almacenar, acceder y analizar datos, para ayudar a los usuarios empresariales a tomar decisiones (Schlesinger & Rahman, 2016). Para lograrlo, es necesario que los usuarios cuenten con herramientas que les faciliten el autoservicio, para que ellos puedan manipular los datos y obtener respuestas a sus preguntas, sin hacer requerimientos a las áreas de informática de las compañías.
El autoservicio se está convirtiendo en la norma en datos y análisis, cada vez más usuarios empresariales exigen acceso a los datos para obtener sus propios conocimientos e impulsar iniciativas (Clarke, Tyrrell, & Nagle, 2016).
2.5. Datos abiertos
Un aspecto por considerar dentro de la arquitectura de plataformas de servicios de datos es el de datos abiertos. Un dato o contenido está abierto si alguien es libre de usarlo, reutilizarlo y compartirlo, sujeto solo al requisito de hacer énfasis en la fuente original. Aplicado a los datos, requiere que un conjunto de datos sea accesible sin costo y sin restricciones técnicas que eviten su uso (Gray & Darbishire, 2011).
2.6. DataOps
Con el propósito de obtener calidad y reducir los tiempos en los ciclos de análisis de datos en la inteligencia de negocios se define DataOps. Esta metodología es un conjunto de prácticas, procesos y tecnologías que se ajustan al flujo continuo de trabajo de la inteligencia de negocios para reaccionar a requisitos imprevistos de una solución, y así permitir el despliegue e integración continua (Ereth, 2018).
3. Revisión de literatura /Antecedentes
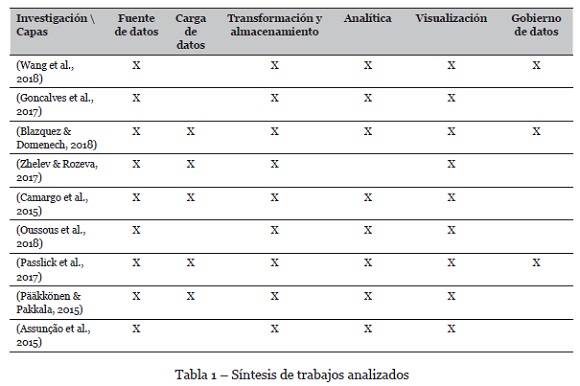
A continuación, se presenta la síntesis de los estudios previos priorizados, los cuales están relacionados con el objeto de estudio y sus fundamentos teóricos ayudan a dar sustento a este trabajo. Se organizan en tres categorías: arquitecturas en un contexto especifico, combinación de arquitecturas y nuevas arquitecturas.
3.1. Aplicación de arquitecturas en un contexto especifico
En el campo de la atención médica, Wang, Kung, & Byrd (2018) desarrollaron una arquitectura de Big Data, la cual se construyó con base en las experiencias de implementación de sistemas de Big Data en la industria, y se compuso de cinco capas: (i) capa de datos, que incluye las fuentes de datos para apoyar las operaciones y la resolución de problemas; (ii), capa de agregación de datos, que se encarga de adquirir, transformar y almacenar datos; (iii) capa analítica, que se encarga de procesar y analizar datos; (iv) capa de exploración, que funciona generando resultados para el apoyo a la decisión clínica. Por último, la capa de gobierno de datos, que se encarga de administrar los datos a lo largo de todo su ciclo de vida. Esta capa es necesaria, dada la sensibilidad de los datos clínicos. Esta arquitectura solo considera los usuarios con experiencia en analítica, dejando de lado aquellos que pueden requerir un mayor procesamiento de datos a la hora de la visualización. Por otra parte, solo son tenidas en cuenta las fuentes de datos estructuradas, quedando por fuera aquellas fuentes no estructuradas que son comunes en la gestión de las organizaciones.
La arquitectura de Big Data en tiempo real, establecida e implementada por Goncalves, Portela, Santos, & Rua (2017) en la unidad de cuidados intensivos del Centro Hospitalario de Porto, en Portugal, responde a las necesidades de la organización y ayuda a tomar decisiones rápidas en servicios críticos del Centro Hospitalario. La arquitectura implementada trabaja con agentes que permiten la ejecución de tareas automáticas como la recopilación de datos y la actualización de modelos predictivos. La solución presentada esta basada en productos de código abierto y deja de lado una gran variedad de herramientas que no tienen esta característica y que pueden ser útiles en otros escenarios. La arquitectura solo puede ser implementada en unidades de cuidados intensivos que tengan especificaciones similares. Una arquitectura de referencia debe ser útil para empresas de diferentes campos y no generar dependencia por el tipo de herramientas tecnológicas que se utilizan.
La arquitectura de Big Data propuesta por Blazquez & Domenech (2018) explica las particularidades de los análisis de comportamiento económico y social en la era digital. La primera particularidad está relacionada con la variedad de fuentes que podrían proporcionar información sobre estos temas, en este punto proponen una taxonomía para clasificar las fuentes de acuerdo con el propósito del generador de datos. La segunda contribución está relacionada con los métodos para procesar los datos y permitir la gestión en una arquitectura robusta y flexible.
Una dificultad es su implementación en un entorno de computación en la nube, y este aspecto es un obstáculo para implementar una plataforma de servicio de datos, que es el objetivo principal en esta investigación.
3.2. Propuestas de combinación de arquitecturas
Zhelev & Rozeva (2017) exponen que es necesario contar con un amplio conocimiento para escoger la arquitectura de datos cuando se trata de temas de Big Data y profundiza en algunas de ellas, enfocándose en las arquitecturas Lambda y Kappa. Ambas presentan dificultades en la implementación y el soporte, debido a que es complejo mantener el procesamiento por lotes y en tiempo real. En la arquitectura de referencia, la organización será la responsable de definir el tipo de procesamiento que se debe realizar sobre los datos, según las necesidades.
Camargo, Camargo, & Joyanes (2015) revisan tres propuestas de arquitectura de Big Data y proponen una que reúne características de cada modelo. La arquitectura propuesta contiene las siguientes etapas: recolección de datos, carga de datos, transformación de datos, extracción de datos y un aspecto de seguridad. En la arquitectura planteada hace falta una etapa para el gobierno de datos, que no solo considere seguridad, sino aspectos como calidad del dato, datos maestros y metadatos, como lo sugieren Khatri & Brown (2010).
Un estudio realizado por Oussous et al. (2018), analiza tecnologías desarrolladas para Big Data, el objetivo es ayudar a seleccionar la combinación correcta de herramientas, de acuerdo con las necesidades tecnológicas y a los requisitos de la organización, proporcionando una visión detallada de la arquitectura. Un resultado del estudio es que existen deficiencias en las herramientas tecnológicas, en la mayoría de los casos relacionadas con la arquitectura y técnicas adoptadas. Atender esta problemática es un objetivo del presente trabajo, a través de una arquitectura de referencia que defina las bases para que una organización pueda establecer su arquitectura de Big Data.
3.3. Propuestas de nuevas arquitecturas
Passlick, Lebek, & Breitner (2017) describen un proceso llamado inteligencia del auto servicio para hacer inteligencia de negocio con Big Data, el objetivo es que los usuarios sean quienes hagan sus informes y los analicen. Se resaltan dos componentes dentro del diseño planteado, las salas de colaboración y una base de datos de conocimiento para el autoaprendizaje, ya que hacen que el conocimiento implícito de los usuarios sea utilizable. La base de datos de conocimiento utiliza un algoritmo de autoaprendizaje, el cual se ve afectado si no se le suministra un gran volumen de datos, en este caso se aplicará una base de datos de conocimiento simple sin el algoritmo. Una dificultad que se presenta con esta arquitectura es el traslado de los componentes a la nube. Además, dicha arquitectura no ha sido probada en un ambiente empresarial.
Pääkkönen & Pakkala (2015) describen una arquitectura de referencia para sistemas de Big Data basada en el análisis de algunos casos de implementación en la industria. En este trabajo se describen las siguientes funcionalidades: fuentes de datos, extracción de datos, carga y preprocesamiento de datos, análisis de datos, transformación de datos, interfaz y visualización. La arquitectura descrita en este trabajo no ha sido evaluada en un caso real con grandes volúmenes de datos y no considera una capa de gobierno de datos para gestionar la seguridad y los metadatos.
Assunção, Calheiros, Bianchi, Netto, & Buyya (2015) identificaron los componentes que deben estar presentes en cualquier arquitectura de Big Data: fuentes de datos, procesamiento de datos, modelado y análisis de resultados y visualización. Esta arquitectura se propuso para ser implementada en la nube, debido a los beneficios que ofrece este componente para almacenar grandes cantidades de datos. En el trabajo futuro se deja descrito el establecimiento de lineamientos para definir la arquitectura en una organización, los cuales serán definidos en esta investigación.
3.4. Síntesis de estudios primarios
A continuación, se presenta una tabla con la síntesis de los estudios primarios y las fases de una arquitectura de Big data que cada investigación ha contemplado.
4. Arquitectura de referencia
La co-creación de la arquitectura de referencia tendrá en cuenta diferentes usuarios del área de Big Data, con los cuales se tendrán sesiones de trabajo para conocer las arquitecturas que actualmente están manejando en sus organizaciones y luego plasmar una arquitectura ideal de Big Data que tenga en cuenta las capas presentadas en el numeral anterior. La elección de una técnica para abordar las sesiones de trabajo, que permita obtener nuevos requisitos y validar las características de la arquitectura de referencia es el primer paso para lograr un acercamiento con los potenciales usuarios, que a futuro podrán hacer uso de la arquitectura para una plataforma de servicio de datos.
El estudio determinó que la combinación de grupos focales con la creación de prototipos facilita la interacción y participación de los usuarios, de forma que ellos puedan expresar abiertamente sus opiniones y proponer nuevas ideas que ayuden a la creación de la arquitectura de referencia. Un grupo focal es un medio para obtener ideas sobre un producto o servicio en un entorno grupal interactivo. La creación de prototipos se utiliza para validar las necesidades de las partes interesadas a través de un proceso que crea un modelo o diseño de requisitos.
Con el propósito de lograr el desarrollo de la arquitectura de referencia se ha tomado la metodología Design Science in Information Systems Research (Hevner, March, Park, & Ram, 2008), la cual tiene como principio que el conocimiento y comprensión de un problema y su solución, se adquieren en la aplicación y construcción de un artefacto. Este principio será aplicado en el diseño de la arquitectura de referencia y el diseño inicial se va refinando en cada avance del proceso de investigación. Las fases de esta metodología son: fase I - Análisis del entorno, fase II - Análisis de la base del conocimiento y fase III - Diseño y validación del modelo.
La fase I - Análisis del entorno, ha sido cubierta con la revisión bibliográfica presentada en el numeral anterior; la fase II - Análisis de la base del conocimiento, contempla las actividades: desarrollo de grupos focales y definición de las capas de la arquitectura, estas actividades se abarcan en los numerales 4.1 y 4.2. Por último, la fase III - Diseño y validación del modelo, que contempla el diseño y evaluación de la arquitectura se desarrolla en el numeral 4.3 y en la evaluación y conclusiones del artículo.
4.1. Bases y fundamentos de la arquitectura
Basados en las investigaciones analizadas se abstraen las siguientes capas para una arquitectura de referencia para plataformas de servicios de datos: fuentes de datos, carga de datos, transformación y almacenamiento, analítica, visualización y gobierno de datos. En la capa de visualización se utilizará el portal o plataforma de servicios de datos para facilitar el auto servicio y el análisis de los usuarios. La capa de gobierno de datos será transversal a todas las demás y permitirá definir quién se hace responsable de la toma de decisiones de la organización y quién debe responder por los datos, esta capa tendrá en cuenta la seguridad, los datos maestros y la metadata.
4.2. Aproximación a la arquitectura de referencia
El diseño de la arquitectura de referencia para plataformas de Big Data fue guiado a partir de un proceso colaborativo con 3 grupos focales. Se realizó la identificación previa de los participantes para garantizar su conocimiento en Big Data y analítica y se dividieron en grupos de trabajo con características similares, según el tipo de industria de la que hacen parte.
Los participantes de cada uno de los grupos focales fueron los siguientes:
- Cuatro empleados de empresas de tecnología con conocimiento en Big Data y analítica.
- 11 personas con conocimiento y experiencia en entornos de Big Data y analítica de Instituciones de Educación Superior de la ciudad de Medellín.
- Dos arquitectos de Big Data de empresas de servicios.
En el desarrollo de cada uno de los grupos focales se ejecutaron las siguientes actividades:
- Presentación de alternativas para implementar arquitecturas de Big Data.
- Los asistentes presentan la arquitectura y herramientas tecnológicas de las plataformas de Big Data que tienen en las empresas.
- Diseño de modelo de arquitectura para plataformas de servicios de datos, teniendo en cuenta 4 capas: repositorios, preparación de datos, modelado y evaluación y visualización.
- Análisis de los modelos de arquitectura construidos e identificación de características comunes.
- Calificación de las características comunes encontradas, para priorizar necesidades.
La identificación de características comunes y la calificación asignada por cada uno de los asistentes a los grupos focales arrojó el resultado que se plasma en la tabla 2.
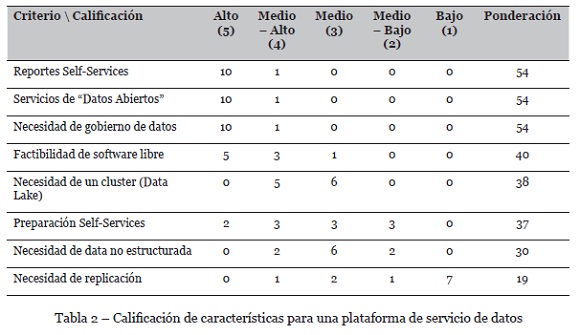
Como se puede observar en la tabla anterior, el auto servicio, los datos abiertos y el gobierno de datos obtuvieron la mayor ponderación, evidenciando que son características con las cuales debe contar una arquitectura de Big Data.
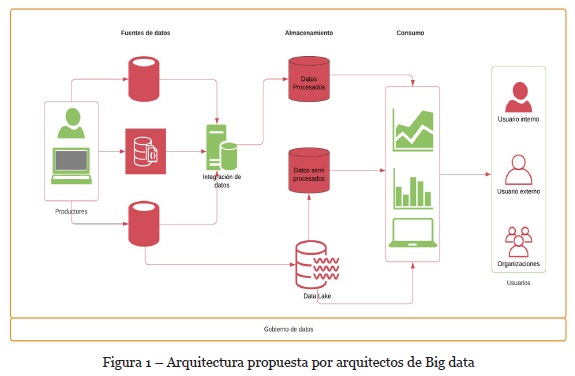
Con el grupo de arquitectos se hizo énfasis en las capas que debe tener una arquitectura de Big Data y sus características principales, como resultado se construyó la arquitectura que se muestra en la figura 1.
Las principales conclusiones de las sesiones de trabajo que se deben tener en cuenta en una arquitectura de referencia de una plataforma de servicios de datos son:
- Es indispensable tener gobierno de datos antes de definir la arquitectura para la plataforma de servicios de datos, con el fin de iniciar el control sobre la información que puede gestionar cada usuario.
- La arquitectura de referencia debe ser escalable y flexible para permitir la auto gestión de los usuarios finales.
- Se deben definir los metadatos, como parte del gobierno, para identificar y estandarizar los nombres de cada uno de los campos que pueden tratar y visualizar los usuarios.
4.3. Representación gráfica de la arquitectura
Con la revisión de literatura y los hallazgos de los grupos focales se propone la arquitectura de referencia para plataformas de servicios de datos, la cual se muestra en la figura 2.
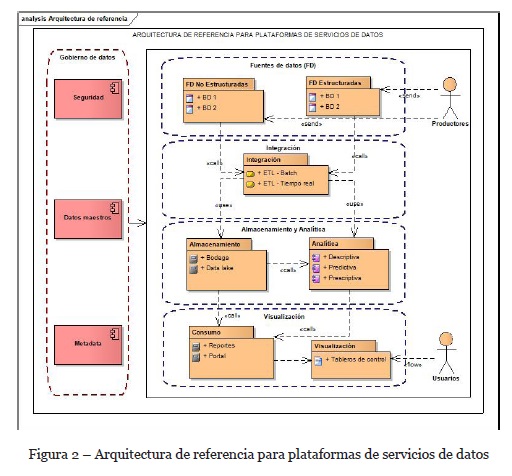
La arquitectura de referencia que se propone para plataformas de servicios de datos tiene en cuenta las siguientes capas: fuentes de datos, integración o procesamiento, almacenamiento, analítica, visualización y gobierno de datos.
Fuentes de datos
El objetivo de esta capa es leer los datos proporcionados por diversos canales, con diversos tamaños y formatos; en esta capa se presenta el primer obstáculo en la implementación de una arquitectura de Big Data, ya que las características de los datos pueden variar considerablemente y la adquisición de componentes para almacenarlos puede exceder el presupuesto (Wang et al., 2018). Ante esta situación cada compañía debe decidir la cantidad y el tipo de datos a los que les dará tratamiento.
Integración o procesamiento
En esta capa se ejecuta la tarea de preparación de los datos, normalmente esta actividad es la más laboriosa y la que regularmente consume más tiempo (Assunção et al., 2015). En esta capa se fusionan los datos en una estructura homogénea, lo que permite que los datos sean rastreables, más fáciles de acceder y manipular (Blazquez & Domenech, 2018).
Las arquitecturas Lambda y Kappa pueden ser tenidas en cuenta en esta capa, dado que ambas permiten el procesamiento por lotes y en tiempo real. Elegir la arquitectura correcta depende de los requisitos de la solución a implementar, si los algoritmos que procesan datos en tiempo real e históricos son los mismos y la solución no necesita cálculos pesados, entonces se podría optar por la arquitectura Kappa. Existen casos en los que no se puede simplificar el procesamiento de datos y sería necesario usar la arquitectura Lambda.
Esta es una de capas en las cuales el gobierno de datos debe incorporar restricciones, ya que los datos integrados pueden facilitar el descubrimiento de información privada y personal que de otro modo sería anónima.
Almacenamiento
En esta capa se almacenan los datos para luego permitir su recuperación y se deben producir los metadatos asociados (Blazquez & Domenech, 2018). Actualmente, existen opciones en la nube que permiten realizar esta tarea, pero deben ser analizadas con detalle, ya que pueden no satisfacer las necesidades de concurrencia y rendimiento de las herramientas utilizadas en el análisis (Assunção et al., 2015).
Una de las actividades a analizar es el costo computacional de transportar los datos del sitio de procesamiento al lugar de almacenamiento, dichos costos deben ayudar a determinar si el lugar de procesamiento debe ser más cercano al de almacenamiento. El almacenamiento de los datos se puede realizar en un lago o en una bodega de datos, esto está determinado por los requisitos de la solución.
Analítica
Esta capa permite el análisis de datos y la obtención e interpretación de resultados. Los métodos estadísticos y de aprendizaje automático deben ser utilizados para extraer conocimiento y hacer predicciones a partir de los datos procesados y almacenados en las capas anteriores. Para lograr este objetivo, se aplican técnicas descriptivas, predictivas y prescriptivas. El análisis descriptivo ayuda a proporcionar ideas sobre las características y la evolución de las diferentes variables de una organización, estos resultados se utilizarán en la capa de visualización para crear tablas y gráficos que representen la relación entre las variables (Blazquez & Domenech, 2018).
El análisis predictivo se basa en modelos que ayudan a explicar, clasificar, y pronosticar la actividad futura de la organización, el comportamiento y las tendencias. Para hacerlo, los modelos se entrenan usando métodos de aprendizaje automático para seleccionar las variables más significativas e ir mejorando las predicciones (Blazquez & Domenech, 2018).
El análisis prescriptivo ayuda a la toma de decisiones determinando acciones y evaluando su impacto con respecto a los objetivos, requisitos y limitaciones del negocio.
Existen diversas formas de realizar este análisis: procesamiento por lotes o en paralelo y procesamiento en tiempo real. La elección de cual técnica escoger estará basada en el tipo de análisis que se debe realizar y esto determinará la herramienta tecnológica que se debe usar (Wang et al., 2018).
En esta capa se deben definir los tipos de usuarios que realizarán el análisis de los datos para determinar qué tipos de herramientas tecnológicas se disponen para dicho fin y el grado de procesamiento que se debe realizar en los datos, de esta manera se podrán facilitar las tareas de autogestión de los diferentes grupos de usuarios (Passlick et al., 2017).
Visualización
En esta capa se generan los informes y se permite el monitoreo de los datos procesados. La presentación de informes es una característica crítica del análisis de Big Data que permite visualizar los datos de una manera útil para respaldar las operaciones diarias y ayudar a la toma de decisiones en las compañías (Wang et al., 2018).
La presentación de los datos se debe dividir según el tipo de usuario que los visualizará. La separación se realiza de acuerdo con la habilidad y la necesidad del usuario (Passlick et al., 2017). En los tableros de control, los usuarios son consumidores de informes predefinidos y allí dan seguimiento a las métricas de desempeño de la organización. Los tableros de control son utilizados, generalmente, por usuarios ocasionales. Otro grupo de usuarios son los científicos de datos, ellos tienen un alto grado de libertad, así como los derechos de acceso y las herramientas para construir sus propios informes. Entre las dos opciones mencionadas anteriormente se encuentra el portal de análisis, allí los informes están predefinidos, pero los usuarios pueden realizar ajustes con restricciones. Las definiciones de grupos de usuarios deben adaptarse a las necesidades de cada organización.
En esta capa aparece la plataforma de servicios de datos para permitir la distribución y diagramación y así facilitar el análisis y la toma de decisiones.
Durante esta etapa el gobierno de datos debe establecer los derechos de autor de los datos e informes visualizados, citando fuentes y dando controles de acceso (Blazquez & Domenech, 2018).
Gobierno de datos
Esta capa es transversal a las demás y allí se deben aplicar las políticas y regulaciones de la organización a todo el ciclo de vida de los datos: desde la ingesta de datos hasta la eliminación (Blazquez & Domenech, 2018). Otros componentes de esta capa son la gestión de datos maestros, la gestión de la seguridad y los metadatos. Esta capa enfatiza en el "cómo" aprovechar los datos en la organización. La gestión de datos maestros está definida como los procesos y estándares para administrar los datos. El componente de seguridad es la plataforma que proporciona actividades para facilitar la evaluación de la configuración, el monitoreo, auditoría y protección de los datos (Wang et al., 2018). Los metadatos permiten identificar y estandarizar los nombres de cada uno de los campos que pueden tratar y visualizar los usuarios.
La capa de gobierno debe tener en cuenta los siguientes módulos: módulo de ingestión, se ocupa de la gestión de las fuentes de datos, los permisos de usuario y la integridad de los metadatos; módulo de procesamiento, realiza un seguimiento de las transformaciones y de los permisos para acceder a los datos; módulo de resultados, se ocupa de los permisos para acceder a los informes y los resultados; módulo de auditoría, inspecciona que la implementación de la arquitectura sea coherente con las políticas de seguridad (Blazquez & Domenech, 2018).
5. Evaluación de la arquitectura
La evaluación de la arquitectura se realiza con base en aspectos planteados en la introducción. Primero, las organizaciones no identifican la forma y las herramientas tecnológicas para gestionar y procesar grandes volúmenes de datos (Jovanovic et al., 2017); frente a este punto, la arquitectura de referencia brinda una guía para que cada organización adopte el camino a seguir para establecer su arquitectura, según las fases que desee aplicar y las herramientas tecnológicas con la que cuente o desee adquirir.
Segundo, las plataformas desarrolladas no facilitan el aumento de la capacidad de trabajo sin comprometer el funcionamiento (Oussous et al., 2018) y se tiene desconocimiento del dominio del problema que se desea atender y de los datos que se procesarán (Zhelev & Rozeva, 2017); ante estas situaciones, identificar las fuentes de datos que serán tratadas es el primer paso para definir todo el proceso de extracción, transformación y análisis de datos y así, no comprometer a futuro el funcionamiento de la arquitectura. La definición de las fuentes de datos debe incluir la cantidad y los tipos de datos a los que se les dará tratamiento, como primer paso para tener claridad del problema que se desea atender.
Con relación al desconocimiento del dominio del problema, es necesario tener entendimiento de la organización, claridad en sus objetivos y comprensión de los datos que se procesarán. El propósito es convertir esos objetivos en objetivos técnicos dentro de la arquitectura y así establecer las capas y procesos que se deben cubrir, así se podrán recolectar los datos correctos y después interpretar los resultados.
Por último, una arquitectura de referencia de una plataforma de Big Data no debe estar ligada a herramientas técnicas particulares y debe incluir los posibles tipos de usuario que la pueden utilizar (Zaghloul et al., 2015); frente a este aspecto, la arquitectura de referencia pretende ser lo suficientemente general para implementarse con diferentes tecnologías, paradigmas informáticos y software analítico, dependiendo de los requisitos y propósitos de cada caso en particular.
6. Conclusiones
El gobierno de datos y la autogestión son dos características que las organizaciones deben incluir en una arquitectura de servicios de datos, con el fin de facilitar el uso de estas plataformas y establecer políticas que regulen el ciclo de vida de los datos.
Es necesario identificar los tipos de usuario que tendrá la plataforma de servicios de datos, ya que ellos serán una de las guías para la construcción de la arquitectura.
La arquitectura de referencia para plataformas de servicios de datos pretende ser lo suficientemente general como para implementarse con diferentes tecnologías, paradigmas informáticos y software analítico, dependiendo de los requisitos y propósitos de cada organización.
Frente a los hallazgos de la revisión del estado del arte, la propuesta de arquitectura de referencia tiene las siguientes diferencias: considera diferentes tipos de usuario y de fuentes de datos, no genera dependencia por el tipo de herramientas tecnológicas que se utilizan, las capas pueden ser implementadas en la nube y se establece una capa para el gobierno de datos.
Dentro de los componentes de la arquitectura establecida, uno de los retos pendientes es la gestión de los flujos intensivos de datos, y requiere una atención especial por parte del mundo académico y de la industria.
La arquitectura de referencia diseñada es la principal contribución de este trabajo, quedando como trabajo futuro la implementación y respectivas pruebas en algún tipo de industria y dentro de un contexto escalable.
Aunque la arquitectura propuesta es lo suficientemente general como para implementarse con cualquier tecnología, su adaptación no está exenta de obstáculos. Para mencionar alguno de ellos, la integración de la arquitectura con los sistemas de información de la organización se convierte en un proceso crítico, el cual debe asegurar la generación de pronósticos y predicciones sin problemas.
REFERENCIAS
Artac, M., Borovsak, T., Di Nitto, E., Guerriero, M., Perez-Palacin, D., & Tamburri, D. A. (2018). Infrastructure-as-Code for Data-Intensive Architectures: A Model-Driven Development Approach. In Proceedings of the 2018 IEEE 15th Intertational Conference of Software Architecture ICSA (pp. 156-165). https://doi.ieeecomputersociety.org/10.1109/ICSA.2018.00025 [ Links ]
Assunção, M. D., Calheiros, R. N., Bianchi, S., Netto, M. A., & Buyya, R. (2015). Big Data computing and clouds: Trends and future directions. Journal of Parallel and Distributed Computing, 79, 3-15. https://doi.org/10.1016/j.jpdc.2014.08.003 [ Links ]
Bibri, S.E. (2019). The anatomy of the data-driven smart sustainable city: instrumentation, datafication, computerization and related applications. Journal of Big Data, 6(59), 1-43. https://doi.org/10.1186/s40537-019-0221-4 [ Links ]
Blazquez, D., & Domenech, J. (2018). Big Data sources and methods for social and economic analysess. Technological Forecasting and Social Change, 130, 99-113. [ Links ]
Camargo Vega, J. J., Camargo Ortega, J. F., & Joyanes Aguilar, L. (2015). Arquitectura Tecnológica Para Big Data. Revista Científica, 21(1), 1-7. https://doi.org/10.14483/udistrital.jour.RC.2015.21.a1 [ Links ]
Clarke, P., Tyrrell, G., & Nagle, T. (2016). Governing self service analytics. Journal of Decision Systems, 25, 145-159. [ Links ]
Dabbéchi, H., Nabli, A., & Bouzguenda, L. (2016). Towards cloud-based data warehouse as a service for big data analytics. In Nguyen N., Iliadis L., Manolopoulos Y., Trawiński B. (eds). Computational Collective Intelligence. ICCCI 2016. Lecture Notes in Computer Science (vol 9876, pp. 180 - 189). Springer. https://doi.org/10.1007/978-3-319-45246-3_17 [ Links ]
Ebner, K., Bühnen, T., & Urbach, N. (2014). Think big with big data: Identifying suitable big data strategies in corporate environments. In Proceedings of the 47th Hawaii International Conference on System Sciences (pp. 3748-3757). https://doi.ieeecomputersociety.org/10.1109/HICSS.2014.466 [ Links ]
Ereth, J. (2018). DataOps - Towards a Definition. Published in LWDA. [ Links ]
Golfarelli, M., & Rizzi, S. (2019). A model-driven approach to automate data visualization in big data analytics. Information Visualization, 19, 24-47. https://doi.org/10.1177/1473871619858933 [ Links ]
Goncalves, A., Portela, F., Santos, M. F., & Rua, F. (2017). Towards of a Real-time Big Data Architecture to Intensive Care. Procedia Computer Science, 113, 585-590. https://doi.org/10.1016/j.procs.2017.08.294 [ Links ]
Gray, J. & Darbishire, H. (2011). Beyond Access: Open Government Data & the Right to (Re)use Public Information. In Access Info Europe and Open Knowledge (pp. 1 - 89). https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2586400 [ Links ]
Hevner, A. R., March, S. T., Park, J., & Ram, S. (2008). Design science in information systems research. Management Information Systems Quarterly, 28, 75 - 105. [ Links ]
Jovanovic, P., Romero, O., & Abelló, A. (2017). A unified view of data-intensive flows in business intelligence systems: A survey. In: A. Hameurlain, J. Küng, R. Wagner (Eds.), Transactions on Large-Scale Dataand Knowledge-Centered Systems XXIX. Lecture Notes in Computer Science (vol 10120, pp. 66-107). http://dx.doi.org/10.1007/978-3-662-54037-4_3 [ Links ]
Kazman, R., Abowd, G., Bass, L., & Webb M. (1993). Analyzing the Properties of User Interface Software Architectures. Computer Science Technical Report Carnegie-Mellon University [ Links ]
Khatri, V., & Brown, C.V. (2010). Designing data governance. Commun. ACM, 53, 148-152. [ Links ]
Krishnan, K. (2013). Data Warehousing in the Age of Big Data. Newnes. [ Links ]
Madden, S. (2012). From databases to big data. IEEE Internet Computing, 16, 4-6. DOI: 10.1109/MIC.2012.50 [ Links ]
Mazumder S. (2016). Big Data Tools and Platforms. In S. Yu & S. Guo (Eds.). Big Data Concepts, Theories and Applications, (pp. 29 - 128). Springer. https://doi.org/10.1007/978-3-319-27763-9_2 [ Links ]
Oussous, A., Benjelloun, F.Z., Ait Lahcen, A., & Belfkih, S. (2018). Big Data technologies: A survey. Journal of King Saud University - Computer and Information Sciences, 30, 431-448. [ Links ]
Pääkkönen, P., & Pakkala, D. (2015). Reference Architecture and Classification of Technologies , Products and Services for Big Data Systems. Big Data Research, 2(4), 166-186. https://doi.org/10.1016/j.bdr.2015.01.001 [ Links ]
Passlick, J., Lebek, B., & Breitner, M. H. (2017). A Self-Service Supporting Business Intelligence and Big Data Analytics Architecture. In Proceedings der 13 Internationalen Tagung Wirtschaftsinformatik (pp. 1126-1140). [ Links ]
Pollock, R., & Dietrich, D. (2009). CKAN: apt-get for the Debian of Data. In Proceedings 26th Chaos Communication Congress. https://fahrplan.events.ccc.de/congress/2009/Fahrplan/events/3647.en.html [ Links ]
Schlesinger, P., & Rahman, N. (2016). Self-Service Business Intelligence Resulting in Disruptive Technology. Journal of Computer Information Systems, 56(1), 11-21. DOI: 10.1080/08874417.2015.11645796 [ Links ]
Wan, J., Cai, H., & Zhou, K. (2015). Industrie 4.0: enabling technologies. In Proceedings of 2015 International Conference on Intelligent Computing and Internet of Things (pp.135-140). IEEE. https://doi.org/10.1109/ICAIOT.2015.7111555 [ Links ]
Wang, Y., Kung, L., & Byrd, T. A. (2018). Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technological Forecasting and Social Change, 126, 3-13. [ Links ]
Zaghloul, M.M., Ali-Eldin, A., & Salem, M. (2015). A process-centric data analytics architecture. In Proceedings of the 9th International Conference on INFOrmatics and Systems (pp. 34-39). IEEE. https://doi.org/10.1109/INFOS.2014.7036705 [ Links ]
Zhelev, S., & Rozeva, A. (2017). Big data processing in the cloud - Challenges and platforms.In AIP Conference Proceedings. https://doi.org/10.1063/1.5014007 [ Links ]
Recebido/Submission: 24/05/2020. Aceitação/Acceptance: 19/08/2020