








Servicios Personalizados
Revista
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Accesos
Accesos
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRISTI - Revista Ibérica de Sistemas e Tecnologias de Informação
versión impresa ISSN 1646-9895
RISTI no.39 Porto oct. 2020
https://doi.org/10.17013/risti.39.67-83
ARTÍCULOS
Mejoramiento del algoritmo ADR en una red de Internet de las Cosas LoRaWAN usando Aprendizaje de Máquina
Improvement of the algorithm ADR in an Internet of Things network LoRaWAN by using Machine Learning
Mauricio González-Palacio 1, Lina María Sepúlveda-Cano 2, Jhon Quiza-Montealegre 1, Juan D’Amato 3
1 Ingeniería de Telecomunicaciones, Universidad de Medellín, 050082, Medellín, Colombia. magonzalez@udem.edu.co, jhquiza@udem.edu.co
2 Ingeniería de Sistemas, Universidad de Medellín, 050082, Medellín, Colombia. lmsepulveda@udem.edu.co
3 Instituto Pladema, Universidad Nacional del Centro de la Provincia de Buenos Aires, B7001BBO, Tandil, Argentina. juan.damato@gmail.com
RESUMEN
El Internet de las Cosas es un paradigma habilitador de la Industria 4.0, donde sensores y actuadores se conectan a Internet. El protocolo LoRaWAN (Long Range Area Network) es uno de los más empleados, y es usado para transmitir información a largas distancias con mínimo consumo energético. Este protocolo implementa el esquema Adaptative Data Rate para mejorar la energía consumida por nodo, que al ser evaluado a través de simulaciones exhaustivas en Omnet++, ha exhibido posibilidades de mejora en el tiempo de convergencia. El presente trabajo muestra una propuesta para el mejoramiento del algoritmo ADR de tal forma que se optimice el consumo energético en redes LoRaWAN. Dentro de la propuesta se comparan diferentes modelos paramétricos y no paramétricos. Los resultados indican que los métodos basados en Máquinas de Vectores de Soporte y en Redes Neuronales Artificiales presentan la mayor exactitud, con un porcentaje por encima del 90% en las estimaciones.
Palabras-clave: Internet de las Cosas; Industria 4.0; consumo energético; LoRaWAN; Aprendizaje de Máquina
ABSTRACT
The Internet of Things (IoT) is an enabling paradigm for Industry 4.0, where sensors and actuators connect to the Internet. The protocol LoRaWAN (Long Range Area Network) is one of the most used in the IoT, and its primary objective is to transmit sensor information over long distances with minimal energy consumption. This protocol implements Adaptive Data Rate scheme to optimize the energy consumed per node, which, when evaluated through exhaustive simulations in Omnet ++, has exhibited opportunities for improvement in convergence time. The present work shows machine learning models based on parametric and non-parametric methods based on Support Vector Machines (SVM) and Artificial Neural Networks (ANN). The results indicate that the SVM and ANN methods have a success rate greater than 90% in the estimated parameters.
Keywords: Internet of Things; Industry 4.0; energy consumption; LoRaWAN; Machine Learning
1. Introducción
Cuatro revoluciones industriales han impactado la economía históricamente: la primera, cuyo impacto fue la invención de la máquina de vapor; la segunda, cuyo impacto fue el uso de la energía eléctrica en un sinnúmero de procesos productivos; y la tercera, cuyo impacto fue la digitalización de datos dentro de la industria, a través de sistemas de automatización, control y supervisión (Lasi, Fettke, Kemper, Feld, & Hoffmann, 2014). La cuarta revolución industrial (o Industria 4.0) permite realizar un análisis inteligente de los datos, para transformar la forma en la cual se ejecutan diversos procesos (Schwab, 2017). Dicha revolución se apropia, entre otros, de técnicas de algoritmia que permiten hacer clasificación y/o regresión de fenómenos. El desarrollo de software se configura como una herramienta imprescindible para habilitar la cuarta revolución industrial (Petrasch & Hentschke, 2016), permitiendo, a través de técnicas de inteligencia artificial, realizar análisis sobre grandes volúmenes de información. El Internet de las Cosas (IoT), a su vez, potencia la cuarta revolución industrial como una fuente de datos sin precedentes para su posterior análisis.
Paradigmas como el Big Data, la robótica, el aprendizaje automático, y el Internet de las Cosas son potenciadores de la Industria 4.0 (Schwab, 2017). El Big Data se define como el tratamiento de grandes volúmenes de información que no pueden ser procesados por esquemas tradicionales de computación en un tiempo tolerable (Chen, Mao, & Liu, 2014). La robótica potencia la maquinaria y su inclusión en la transformación digital de las plantas productivas. La Inteligencia Artificial (IA) predice y clasifica comportamientos con intervención mínima del ser humano (Lee, Davari, Singh, & Pandhare, 2018). El IoT permite, a través de la dotación de objetos de la cotidianidad con sensores y actuadores, conocer el comportamiento de procesos e incidir sobre ellos (Wollschlaeger, Sauter, & Jasperneite, 2017). El análisis de las características de conectividad, en particular en el consumo energético en redes de Internet de las Cosas, son el interés principal en el presente artículo.
En sitios donde no se puede depender de un operador de red, las redes de baja potencia y área amplia (LPWAN) se ajustan para transferir pequeños paquetes de información. Las tecnologías líderes en el mercado actualmente son: LoRaWAN (Sornin, Luis, Eirich, Kramp, & Hersent, 2015), Sigfox (Lavric, Petrariu, & Popa, 2019) y NB-IoT (Ratasuk, Vejlgaard, Mangalvedhe, & Ghosh, 2016). El consumo energético es uno de los factores más críticos en el diseño de una red de IoT, ya que está pensada, en una gran cantidad de casos, para operar con baterías y durante tiempos prolongados. El presente artículo muestra una mejora del algoritmo ADR (Adaptative Data Rate) (San Cheong, Bergs, Hawinkel, & Famaey, 2017) del protocolo LoRaWAN, que se logra por medio del uso de Máquinas de Vectores de Soporte (SVM) y Redes Neuronales Artificiales (ANN). Tal modelación se logra a través de simulaciones exhaustivas en Omnet ++.
El presente trabajo se organiza como sigue: en la sección 2 se condensa el marco teórico requerido para la lectura expedita del trabajo, enfocado al protocolo LoRaWAN; en la sección 3 se muestra el trabajo previo que se ha adelantado para mejorar el consumo energético en redes LoRaWAN; en la sección 4 se muestra el diseño metodológico y experimental; en la sección 5 se muestra la modelación propuesta; en la sección 6 se muestra la propuesta del algoritmo para el mejoramiento del esquema ADR y su evaluación; finalmente, se presentan el trabajo futuro, las conclusiones y las referencias.
2. Marco teórico
Con respecto al componente arquitectónico, las redes LoRaWAN operan usando los siguientes componentes (de Carvalho Silva, Rodrigues, Alberti, Solic, & Aquino, 2017): (i) nodos, que incluyen sensores, sistemas embebidos y radios para transportar los datos recolectados; (ii) gateways, que se encargan de recibir información de los nodos y reenviarla a un servidor de red; (iii) servidor de red, el cual provee un servicio para recolectar los mensajes de diversos gateways y reenviarlos a demanda a algún servidor de aplicación, y de implementar esquemas como el ADR; y (iv) servidor de aplicación, donde se realizan las labores de despliegue y análisis de datos.
En cuanto a la utilización del espectro, el protocolo LoRaWAN opera en la banda ISM (Industrial - Scientific - Medical) que no requiere licencia[1]. En América, la banda usada es 902-928MHz, y en Europa, 862 a 870 MHz (Sornin et al., 2015). Cada región define los canales permitidos para subida y bajada. En cuanto al uso apropiado del espectro, entidades como la FCC (Federal Communications Commission) y la ETSI (European Telecommunications Standards Institute) se encargan de dar directrices para permitir su uso colectivo.
LoRaWAN usa la modulación Chirp Spread Spectrum (CSS) (Reynders & Pollin, 2016). Los canales pueden tener anchos de banda (BW) de 125 kHz, 250 kHz y 500 kHz, dependiendo del plan de frecuencia. Si la frecuencia central es f0, una señal conocida como chirp se mueve en el intervalo (f0 - BW/2, f0 + BW/2), durante un tiempo de símbolo Ts. El número de bits por símbolo se conoce como Spreading Factor (SF) y puede variar entre 7 y 12. El espectro se divide en 2SF posibles frecuencias de inicio (chips), de tal manera, en un mismo símbolo puede incluir 2SF diferentes números. Para agregar bits de redundancia, es posible usar el Coding Rate (CR) que puede tomar valores entre 1 y 4. La rata de chips (Rc) es homóloga al ancho de banda y se define en la ecuación (1). La rata de símbolos se define en función del ancho de banda y el SF, como se indica en la ecuación (2), así como el tiempo de símbolo Ts. La rata de bits, data rate, se define en la ecuación (3).
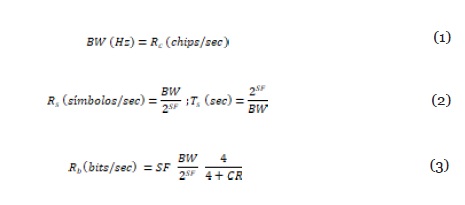
De las ecuación (2) y (3) se puede deducir que para valores mayores de SF, el tiempo de símbolo también será mayor, permitiendo mayores distancias y mayor consumo. Con respecto a los parámetros de diseño, se definen el duty cycle (dc) y el Time on Air (ToA). Los dc son períodos en los cuales un nodo no transmite ninguna información, después de haber hecho una transmisión (Adelantado et al., 2017). El dc puede tomar valores de 0.1%, 1% o 10%, e indica la proporción de tiempo usada para realizar la transmisión. El ToA indica el tiempo que tarda un paquete de información en ser enviado. Así, el tiempo que debe esperarse para realizar una nueva transmisión desde un nodo se define en función del dc y el ToA como se muestra en la ecuación (4).

Donde Tnt indica el tiempo para efectuar una nueva transmisión. A su vez el ToA se define en la ecuación (5).
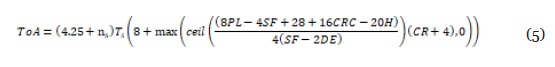
Donde ns es el número de preámbulos (típicamente 8), PL es el tamaño en bytes del payload, CRC es una variable binaria que indica si se incluye comprobación por redundancia cíclica, H indica si el tipo de trama es implícito o explícito y DE si se activa la función low data rate optimization, el cual se activa para valores de ToA mayores a 100 milisegundos (obligatorio para valores de SF de 11 y 12). Para determinar los valores óptimos de SF y la potencia de transmisión TP de un nodo es posible habilitar el algoritmo ADR, ejecutado en el servidor de red (Sornin et al., 2015). Dicho servidor se encarga de recolectar los últimos veinte valores de relación de señal a ruido (SNR) y los data rate usados (por ejemplo, SNR = 5 dB, DR = SF12BW125), y procede a tomar el valor máximo. El servidor de red aplica la ecuación objetivo descrita en (6).

Donde linkbudgetdefault indica el nivel de seguridad, por encima de la sensibilidad del radio, SNRlimit indica la relación de señal a ruido límite que varía con el SF (a mayor SF, mejor sensibilidad de recepción del radio), SNRmeasured es el valor máximo de la SNR medida y margincorrected es la variable objetivo de optimización, cuyo valor debe ser mayor a cero. Nótese que, si las distancias son grandes, puede requerirse tener valores de SF y TP altos. No obstante, después de realizar las mediciones, el valor de margincorrected puede estar lejos de cero, indicando un desperdicio en el TP y un ToA elevado. Así pues, el servidor de red ajusta el SF y recalcula el margen. Si incluso el margincorrected no es cero, se ajusta TP para bajar la potencia de transmisión del radio. Las simulaciones implementadas muestran que el tiempo de convergencia de este algoritmo es susceptible de mejora (Li, Raza,& Khan, 2018).
3. Trabajo previo
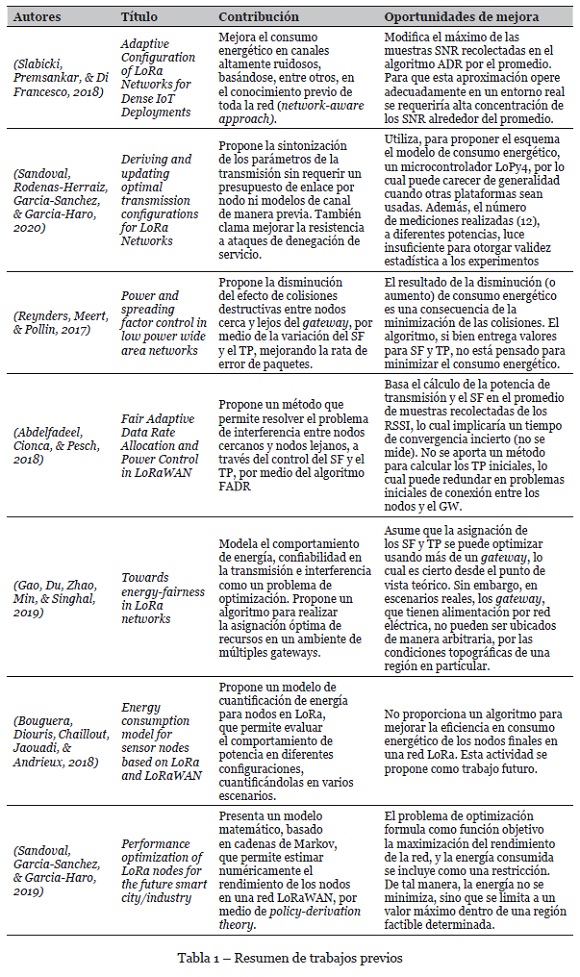
Los trabajos de la literatura relacionados más representativos se muestran en la Tabla 1. Las aproximaciones de manejo energético en la literatura abordan diferentes perspectivas, la mayoría proponiendo valores para SF y TP, pero optimizando otras métricas diferentes a la energía, tales como la capacidad, la confiabilidad y el rendimiento en general y no se enfocan a la minimización de la energía. También se prevén métodos usando la recolección de algunos parámetros como la SNR y la RSSI durante un tiempo suficiente que permita estabilizarlos en un ambiente real, por lo cual el tiempo de convergencia puede ser incierto. Finalmente, diferentes propuestas plantean problemas de optimización que consideran la energía como una restricción, esto es, se limitan a fijar un valor máximo, no a encontrar su valor mínimo. En virtud de los hallazgos, se observa la oportunidad de proponer un método que mejore el consumo energético a partir de la aplicación de modelos que lo optimicen.
4. Metodología y diseño experimental
Primero, se propone la simulación de una red LoRaWAN con 1000 nodos, 1 gateway y 1 servidor de red. Se escogen 1000 nodos para garantizar significancia en los datos de la simulación. A su vez, se usa 1 gateway y un servidor de red dado que ésta es una configuración típica en este tipo de redes. Los valores de TP (2-14 dBm) y SF (7-12) se inicializan de manera aleatoria, así como la posición de los nodos, en una geometría de 1 km2 de área. El gateway se ubica en el centro de la región. Se considera que cada nodo transmitirá un mensaje de manera aleatoria (distribución exponencial) en un intervalo de 0 a 100 segundos. El tiempo de simulación se fija a un día, ya que se encuentra un balance adecuado entre el tamaño de la base de datos generada y la convergencia del algoritmo ADR. El ancho de banda se fija a 125 kHz, el más común para canales de subida en los diferentes planes de frecuencia por región. Con respecto a la herramienta de simulación, se usa Omnet ++ V5.2.1 y el complemento FLoRa (Slabicki et al., 2018). Se habilita el algoritmo tradicional ADR para escogencia de los parámetros SF y TP.
Como segundo paso, para la modelación de la base de datos, se tienen en cuenta los argumentos de entrada distancia (D), TPinicial, SFinicial. Se toma la razón entre la energía consumida por un nodo y la cantidad de paquetes enviados como salida del modelo (EPP), así como el TPfinal, el SFfinal y el tiempo Tc que le toma al algoritmo ADR converger a dichos valores. Se construye la base de datos a través de las corridas de simulación respectivas.
En el tercer paso, con los valores obtenidos de energía/paquete y TP para los diferentes casos de D, TPinicial y SFinicial, se evalúa la modelación a través de regresión lineal múltiple, modelos lineales generalizados (GLM) y SVM.
En cuarto lugar, se evalúan modelos de aprendizaje de máquina supervisados (regresión logística, SVM y ANN) con los mismos argumentos de entrada.
En quinto lugar, se observa el rendimiento de los métodos empleados y se escoge el que exhibe mejores resultados. La aproximación de evaluación divide la base de datos, de manera aleatoria, en 80% de muestras para entrenamiento y 20% para validación. Finalmente, se valida la mejora de energía contrastando el tiempo Tc para hallar los parámetros TP y SF a través del algoritmo ADR y por medio de la aplicación de los modelos propuestos.
5. Modelación
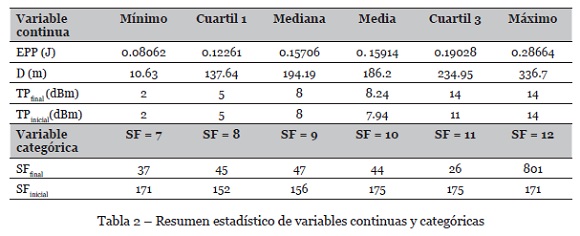
Para el análisis de datos se usa el software R Studio v1.2. Se muestran los análisis para las tres métricas de salida: energía/paquete (EPP), TPfinal y SFfinal. El resumen estadístico de las variables continuas y categóricas se muestra en la Tabla 2.
5.1. Energía por paquete transmitido (EPP)
Regresión lineal múltiple
Se evalúa la regresión lineal múltiple siguiendo el modelo en la ecuación (7).

Los estimadores se muestran en la Tabla 3.
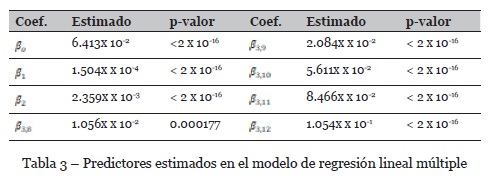
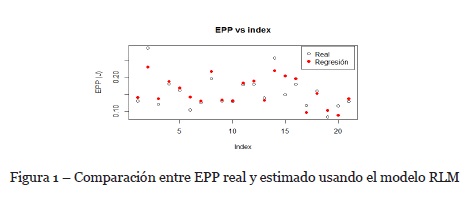
Los p-valores indican que todos los predictores son significativos. El modelo entrega un R2 múltiple de 0.7686 y un R2 ajustado de 0.7667, que indica una correlación lineal fuerte entre las variables predictoras y la variable dependiente EPP. En la Figura 1 se muestra el comportamiento de algunos de los puntos reales vs los predichos por el modelo. Se omite el conjunto completo para garantizar la legibilidad en la lectura. En orden de asegurar la validez estadística del modelo, se implementa el análisis de varianza, encontrando p-valores del orden de 2 x 10-16, mostrando que, en efecto, todas las variables son significativas. Adicionalmente, deben garantizarse los supuestos de normalidad, independencia y homocedasticidad de los residuales. En el primer caso se aplica la prueba de Kolmogorov Smirnov fijando un nivel de significación de 5%, y entregando un valor p de 5.793%. En el caso de independencia, se aplica la prueba de Durbin Watson, entregando un DW=1.9907, indicando independencia entre las variables predictoras. Finalmente, para garantizar homocedasticidad, se aplica la prueba de Breusch Pagan, obteniendo un valor p <2 x 10-16, indicando que los residuales son heterocedásticos. En tal virtud, el modelo pierde eficiencia en sus estimadores de mínimos cuadrados, aunque sigue siendo insesgado (E(X)=X).
Modelos lineales generalizados
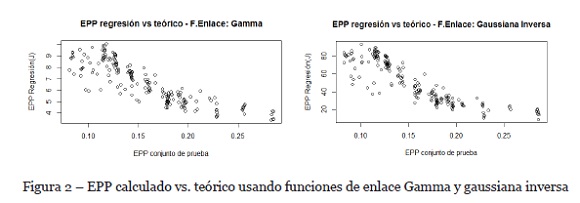
Dado que se tiene heterocedasticidad, se recomienda utilizar un modelo lineal generalizado con diferentes funciones de enlace: Gamma y gaussiana inversa. Las funciones de enlace binomial y Poisson no se consideran por el tipo de proceso que se está modelando. Los coeficientes de los modelos se estimarán utilizando el criterio de máxima verosimilitud (MLE). La calidad de los modelos se evaluará utilizando el índice AIC y la calidad de las predicciones usando el R2. Con la función Gamma se logra un AIC de -3918, un R2 de 0.71 y un RMS de 0.69; y con la gaussiana inversa se logra un AIC de 3828, un R2 de 0.74 y un RMS de 6.7. Si bien se observa una relación a través del R2, usando ambos modelos, también se observa que los errores cuadráticos medios están en órdenes de magnitud mucho mayores que los de los datos. Esta lectura indica que ambos modelos fallan en las regresiones. Si se grafica el EPP del modelo vs EPP teórico (ambos del subconjunto de pruebas), se esperaría una tendencia lineal positiva; no obstante, se obtiene lo graficado en la Figura 2. Por tal motivo, no se publican los valores del modelo, ya que no hay un ajuste satisfactorio.
Máquinas de vectores de soporte (SVM)
Se procede a aplicar regresión a través de SVM (Noble, 2006). En el caso de clasificación con SVM, se busca el hiperplano que separe dos clases con el máximo margen entre ambas, por lo cual, encontrar el modelo se reduce a un problema de optimización, donde deben hallarse los coeficientes w que definen dicho hiperplano, como se muestra en la ecuación (8).
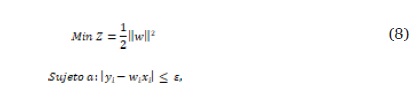
donde yi corresponde a las características objetivo, wi a los pesos y xi a las características de entradas. En el caso de regresión, se agrega a la ecuación (8) un conjunto de variables de holgura, y así, para cada valor que cae por fuera de ε, se registra su desviación ξ, de tal manera que se desea que ésta sea mínima. Se introduce el hiper parámetro costo (C) para penalizar dichas desviaciones, el cual es sintonizado a través de validación cruzada. De tal manera, la ecuación (8) se reescribe como se muestra en la ecuación (9).
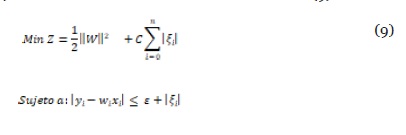
Para el caso de EPP, se toman como características de entrada las mismas usadas en los métodos paramétricos: D, TPinicial y SFinicial y las características objetivo son los valores de EPP. Para realizar las evaluaciones, se usan cuatro tipos diferentes de kernels: lineal (RMS=0.025, R2=0.75), polinomial (no converge), sigmoidal (RMS=0.029, R2=0.714) y de base radial (RMS=0.02, R2=0.837). De acuerdo con las métricas presentadas, y a una inspección visual (mostrada en la Figura 3a), el kernel de base radial (RBF) es el que se ajusta mejor a los datos. El RBF se considera una medida de similitud modificada (calculada a partir de la distancia euclidiana), y extrapola el espacio de características a infinitas dimensiones. El RBF entre dos muestras se calcula como:
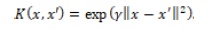
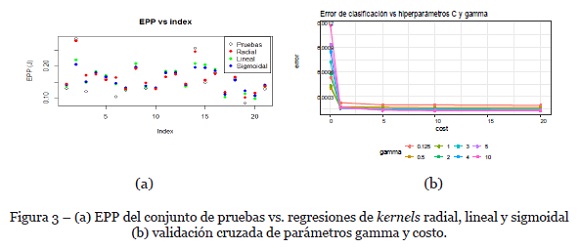
El hiper parámetro γ se debe sintonizar a través de validación cruzada. Para escoger los hiper parámetros C y γ se usa el software R Studio, librería e1071, método tune. La Figura 3b muestra la comparación de los errores de clasificación usando diferentes configuraciones de C y γ, de donde se deduce que, para diferentes conjuntos de entrenamiento, los mejores valores son C=10 y γ=10. Se omite la escritura de los vectores de soporte encontrados, dada su cantidad: 439.
5.2. Potencia de transmisión final (TPfinal)
Los análisis de RLM, GLM y SVM realizados en este aparte se analizan bajo la misma óptica de la sección 5.1., por lo cual se omitirán los detalles y se procederá a ilustrar los resultados. En todos los casos TPfinal será una función de D, TPinicial y SFinicial.
Regresión lineal múltiple

Modelos lineales generalizados
Al aplicar la función de enlace gamma se obtiene un AIC de 3755, un R2 de 0.91 y un RMS de 9.24. Al aplicar la gaussiana inversa se obtiene un AIC de 4303, un R2 de 0.91 y un RMS de 9.48. El comportamiento exhibido es similar al observado en la Figura 2. Dado que la tendencia debería ser lineal y no se obtiene este comportamiento, se concluye que GLM no ajusta adecuadamente los datos, por lo cual no se publican los resultados de los modelos.
Máquinas de vectores de soporte (SVM)
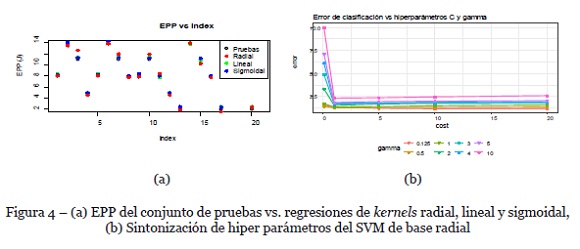
Se realizan las evaluaciones con cuatro tipos diferentes de kernels: lineal (RMS=1.2686, R2=0.91307), polinomial (no converge), sigmoidal (RMS=1.27548, R2=0.91159) y RBF (RMS=0.9196, R2=0.955). Dado que RBF es el que logra los mejores resultados con el conjunto de pruebas (Figura 4a), se procede a sintonizar los hiper parámetros C y γ, cuyos resultados se muestran en la Figura 4b. Los mejores valores son C=20 y γ=0.125. Se omite la publicación de los vectores de soporte, debido a su número: 244.
5.3. Número de bits por símbolo (Spreading Factor) final (SFfinal)
Dado que el parámetro SFfinal es de tipo categórico, el análisis paramétrico se realizará a través de regresión logística múltiple y el no paramétrico con la estrategia de clasificación de SVM y usando ANN. En todos los casos TPfinal será una función de D, TPinicial y SFinicial.
Regresión logística multinomial
Sea Y={1,2, 3,…,n} una variable politómica cuyas probabilidades de ocurrencia son p1, p2,…,pn correspondientemente, las cuales se desean estimar a partir de un conjunto de características de entrada x1,.., xm. Se define cada pj como se muestra en la ecuación (10).
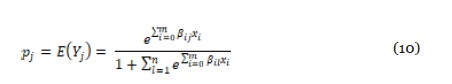
Donde los βij son los regresores que desean ser estimados, a través del criterio de máxima verosimilitud. Para el caso particular de la estimación del SFfinal, la probabilidad de que una nueva observación pertenezca a pj (j = 7, 8,…,12) se puede reescribir a partir de (9), como se muestra en la ecuación (11).
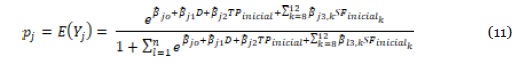
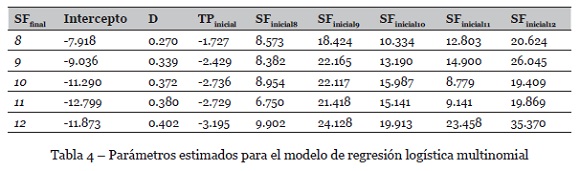
De tal manera, se tendrán 8 regresores por cada clase, y debido a que se tienen valores de SFfinal = 7, 8,…,12, se tendrán 5 probabilidades (SFfinal = 8,…,12), debido a que SF = 7 se considera como una variable de referencia. Así, el número de parámetros a ajustar será de 40, y se muestran en la Tabla 4. Se usa el software R Studio, librería nnet, método multinom.
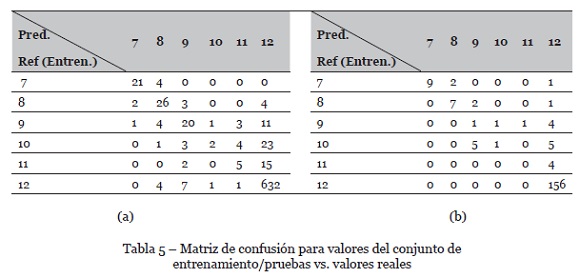
La evaluación se implementa generando una matriz de confusión (librería caret, método confusionMatrix), la cual contrasta los valores estimados vs. los valores esperados y realiza el conteo de aciertos y fracasos, y se muestra en la Tabla 5a (conjunto de entrenamiento) y Tabla 5b (conjunto de pruebas). Puede observarse que, si bien hay casos en los cuales hay éxito en las predicciones, i.e. SFfinal=7,8 y 12, hay otros casos en los cuales no se hacen predicciones correctas, i.e. SFfinal=10,11. La exactitud del modelo es 88.3%, y el intervalo de confianza (IC) [85.81%, 90.4%].
Máquinas de vectores de soporte (SVM)
Se realizan las evaluaciones con cuatro tipos diferentes de kernels (que se evalúan por medio de una matriz de confusión): lineal (exactitud: 86% IC 5%: (80.41%, 90.49%)), polinomial (no converge), sigmoidal (exactitud: 86.5% IC 5%: (83.93%, 88.79%)), y de base radial (exactitud: 85% IC 5%: (79.28%, 89.65%)). Dado que el kernel sigmoidal es el que entrega mejores resultados, se procede a sintonizar los hiper parámetros C y γ, cuyos valores son 5.1 y 0.125 respectivamente. No obstante, se presenta el mismo problema ilustrado en la regresión logística: no hay predicciones correctas para SFfinal de 10 y 11, presentándose cero coincidencias, como se muestra en la Tabla 5. Se concluye que la SVM óptima hallada no es un clasificador válido para el problema en cuestión.
Redes neuronales artificiales (ANN)
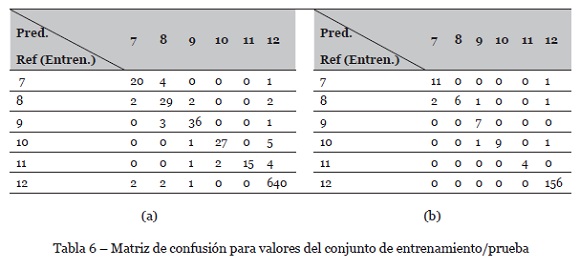
Un método alternativo para lidiar con el problema exhibido por la SVM es usar ANN. Dicho método exhibe algunas desventajas con respecto a las SVM, relacionado con el overfitting (sobre entrenamiento), el cual puede redundar en regresiones o clasificaciones erróneas. A su vez, el riesgo se calcula a partir de la minimización de una función de pérdida (normalmente gradiente descendente) de los datos de entrenamiento (conocido como riesgo empírico), lo cual puede redundar en generalización errónea, a diferencia de las SVM. Por tal motivo, es muy importante el entrenamiento exhaustivo hasta encontrar el modelo que reduzca el overfitting y generalice adecuadamente, lo cual requiere muchos recursos de hardware en conjuntos de datos de gran tamaño. Se presenta una ANN para solucionar el problema de predicción errónea de los SF finales. Se busca el mejor modelo a partir del paquete CARET de R, método train, configurando una grilla que varía los parámetros intrínsecos de la red (número de capas, número de neuronas por capa, decay, entre otros) y calcula un nuevo modelo por cada configuración de parámetros. La métrica de desempeño es el acierto (accuracy). Para asegurar el mejor modelo, se configuran 100 épocas. Se encuentra una ANN perceptrón con 7 neuronas de entrada (D, SFinicial i-ésimo (i= 8,..,12) y TPinicial), 8 neuronas en una única capa oculta, y 6 neuronas de salida (SFfinal i-ésimo (i=7,..,12)). La evaluación de la clasificación se hace usando una matriz de confusión, como se muestra en la Tabla 6. Puede observarse que los errores de clasificación mejoran con respecto a los dos métodos anteriores, exhibiendo una exactitud de 95% en el conjunto de entrenamiento y en el de prueba de 96%.
6. Método propuesto y evaluación
Una vez inferidos los algoritmos con mejor desempeño para inferir los parámetros TPfinal y SFfinal, se propone el Algoritmo 1. Dicho algoritmo se piensa para ser ejecutado en el servidor de red, de tal manera, los nodos enviarán la información necesaria al mismo: TPinicial, SFinicial y la distancia D desde el nodo hasta el gateway más cercano. Por seguridad, se recomienda inicializar los parámetros TP y SF a sus valores máximos, y así se garantizará la entrega del primer paquete de información al servidor de red. Una vez el servidor recibe los parámetros, procede a calcular los valores mejorados, a través de SVM (en el caso de TP) y ANN (en el caso de SF), como se discutió en las secciones previas.
Para comparar la efectividad de los métodos propuestos para la estimación de los parámetros TP y SF, se analiza el tiempo de convergencia del algoritmo tradicional ADR vs. el tiempo que tarda el método propuesto en este trabajo. Al realizar la evaluación con respecto al parámetro TP, se encontró a través de las simulaciones que, de los 1000 nodos, 120 requirieron el ajuste del TP a través de ADR. El mínimo número de veces que el nodo debió solicitar ajustar el TP fue 20, y el máximo fue 485. Teniendo en cuenta el TP inicial, es posible hallar la potencia consumida en la transmisión en watts, si se tiene en cuenta que W = 10TP/10/1000. Al realizar los cálculos, se encontraron potencias mínimas iniciales por paquete de 1.5 x 10-3 w y máximas iniciales de 2.5 x 10-2 w, las cuales fueron inicializadas de manera aleatoria.
En tal virtud, es posible calcular la energía consumida en exceso por las retransmisiones, si se conoce el ToA (ecuación 5). Utilizando los parámetros de la simulación (BW = 125 kHz, min SF = 7, max SF = 12, Coding rate = 1, longitud del payload = 10 bytes), es posible inferir que el mínimo ToA es igual a 0.041 segundos y el máximo a 0.991 s. Así, la energía consumida en exceso (para SF = 7) puede oscilar entre 0.002 J y 0.318 J y la energía consumida en exceso (para SF = 12) puede oscilar entre 0.062 J y 7.67 J. Ahora bien, dado que el método que se propone en este trabajo sólo requiere enviar de manera satisfactoria desde el nodo hasta el gateway los parámetros iniciales TP, SF y distancia, el costo energético para el nodo para ajustar el algoritmo de control de energía será equivalente a una única transmisión/ recepción, la cual, en función de los valores de retransmisión enunciados previamente, pueden estar en proporciones desde 1/485 hasta 1/20, es decir, el método logra reducir, porcentualmente, la energía consumida por el algoritmo ADR tradicional al 5%, en el peor de los casos, lo cual exhibe una mejora sustancial en consumo energético.
En cuanto al tiempo de convergencia, se encontró que el tiempo mínimo para hallar el valor óptimo fue de 1871 s, y el máximo fue de 86.314 s; no obstante, dicho tiempo está en función de las transmisiones que haga cada nodo, las cuales fueron aleatorizadas a través de una distribución exponencial.
7. Conclusiones y trabajo futuro
En el presente trabajo se presentó un método basado en técnicas no paramétricas de aprendizaje de máquina que permiten estimar la potencia consumida en un nodo de Internet de las Cosas que transmita información a través del protocolo LoRaWAN. Para recolectar los datos, se usó el simulador Omnet++ usando el framework FLoRa, en el cual se desplegaron 1000 nodos. La energía consumida en un nodo, como se mostró, depende de la distancia, la potencia de transmisión y el número de bits por símbolo, valores que son sintonizados a través del algoritmo ADR provisto por el protocolo LoRaWAN. Se mostró que la cantidad de paquetes transmitidos para sintonizar dichos valores oscila entre 20 y 485, exhibiendo una posible mejora para el tiempo de convergencia, y de esta manera, una reducción en el consumo energético. Del conjunto de métodos evaluados, se encontró que las máquinas de vectores de soporte (SVM) son efectivas para la regresión de energía por paquete (EPP) y para ajustar la potencia de transmisión (TPfinal), en tanto las redes neuronales son efectivas para clasificar el valor del número de bits por símbolo (SFfinal). Se propone un algoritmo para modificar el ADR tradicional, el cual corre en el servidor y asegura la convergencia de los parámetros SFfinal y TPfinal en una única transmisión/recepción por nodo. Se planea, como trabajo futuro, realizar la implementación física en un ambiente de radio definido por software, para asegurar la validez de los modelos y métodos propuestos en un ambiente de operación real.
REFERENCIAS
Abdelfadeel, K. Q., Cionca, V., & Pesch, D. (2018).Fair adaptive data rate allocation and power control in lorawan. Paper presented at the 2018 IEEE 19th International Symposium on" A World of Wireless, Mobile and Multimedia Networks"(WoWMoM). [ Links ]
Adelantado, F., Vilajosana, X., Tuset-Peiro, P., Martinez, B., Melia-Segui, J., & Watteyne, T. (2017).Understanding the limits of LoRaWAN. IEEE Communications magazine, 55(9), 34-40. [ Links ]
Bouguera, T., Diouris, J.-F., Chaillout, J.-J., Jaouadi, R., & Andrieux, G. (2018). Energy consumption model for sensor nodes based on LoRa and LoRaWAN. Sensors, 18(7), 2104. [ Links ]
Chen, M., Mao, S., & Liu, Y. (2014). Big data: A survey. Mobile networks and applications, 19(2), 171-209. [ Links ]
de Carvalho-Silva, J., Rodrigues, J. J., Alberti, A. M., Solic, P., & Aquino, A. L. (2017). LoRaWAN-A low power WAN protocol for Internet of Things: A review and opportunities. In Proceedings of the 2017 2nd International Multidisciplinary Conference on Computer and Energy Science (SpliTech). [ Links ]
Gao, W., Du, W., Zhao, Z., Min, G., & Singhal, M. (2019). Towards Energy-Fairness in LoRa Networks. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS). [ Links ]
Lasi, H., Fettke, P., Kemper, H.-G., Feld, T., & Hoffmann, M. (2014). Industry 4.0. Business & information systems engineering, 6(4), 239-242. [ Links ]
Lavric, A., Petrariu, A. I., & Popa, V. (2019). Long range sigfox communication protocol scalability analysis under large-scale, high-density conditions. IEEE Access, 7, 35816-35825. [ Links ]
Lee, J., Davari, H., Singh, J., & Pandhare, V. (2018). Industrial Artificial Intelligence for industry 4.0-based manufacturing systems. Manufacturing letters, 18, 20-23. [ Links ]
Li, S., Raza, U., & Khan, A. (2018). How Agile is the Adaptive Data Rate Mechanism of LoRaWAN? In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM). [ Links ]
Noble, W. S. (2006). What is a support vector machine?. Nature biotechnology, 24(12), 1565-1567. [ Links ]
Petrasch, R., & Hentschke, R. (2016). Process modeling for Industry 4.0 applications: Towards an Industry 4.0 process modeling language and method. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE). [ Links ]
Ratasuk, R., Vejlgaard, B., Mangalvedhe, N., & Ghosh, A. (2016). NB-IoT system for M2M communication. In Proceedings of the the 2016 IEEE wireless communications and networking conference. [ Links ]
Reynders, B., Meert, W., & Pollin, S. (2017). Power and spreading factor control in low power wide area networks. In Proceedings of the 2017 IEEE International Conference on Communications (ICC). [ Links ]
Reynders, B., & Pollin, S. (2016). Chirp spread spectrum as a modulation technique for long range communication. Paper presented at the 2016 Symposium on Communications and Vehicular Technologies (SCVT). [ Links ]
San Cheong, P., Bergs, J., Hawinkel, C., & Famaey, J. (2017). Comparison of LoRaWAN classes and their power consumption. Paper presented at the 2017 IEEE symposium on communications and vehicular technology (SCVT). [ Links ]
Sandoval, R. M., Garcia-Sanchez, A.-J., & Garcia-Haro, J. (2019). Performance optimization of LoRa nodes for the future smart city/industry. EURASIP Journal on Wireless Communications and Networking, 2019(1), 1-13. [ Links ]
Sandoval, R. M., Rodenas-Herraiz, D., Garcia-Sanchez, A.-J., & Garcia-Haro, J. (2020). Deriving and Updating Optimal Transmission Configurations for Lora Networks. IEEE Access, 8, 38586-38595. [ Links ]
Schwab, K. (2017). The fourth industrial revolution. Penguin Random House Grupo Editorial España, [ Links ] 2016.
Slabicki, M., Premsankar, G., & Di Francesco, M. (2018). Adaptive configuration of LoRa networks for dense IoT deployments. Paper presented at the NOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium. [ Links ]
Sornin, N., Luis, M., Eirich, T., Kramp, T., & Hersent, O. (2015). Lorawan specification. LoRa alliance. https://www.lora-alliance.org [ Links ]
Wollschlaeger, M., Sauter, T., & Jasperneite, J. (2017). The future of industrial communication: Automation networks in the era of the internet of things and industry 4.0. IEEE industrial electronics magazine, 11(1), 17-27. [ Links ]
Agradecimientos
A la Universidad de Medellín por financiar el trabajo de investigación “Esquema algorítmico para la transmisión de información que minimice el consumo energético y mejore el uso del espectro radioeléctrico en dispositivos de internet de las cosas”, código de proyecto 1039, y por la beca de estudios doctorales otorgada a uno de los autores.
Recebido/Submission: 20/07/2020. Aceitação/Acceptance: 16/09/2020
[1] https://www.thethingsnetwork.org/docs/lorawan/frequencies-by-country.html