








Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkRISTI - Revista Ibérica de Sistemas e Tecnologias de Informação
versão impressa ISSN 1646-9895
RISTI no.25 Porto dez. 2017
https://doi.org/10.17013/risti.25.18-33
ARTÍCULOS
JK-Meta-Biplot y STATIS Dual como herramientas de análisis de tablas textuales múltiples
JK-Meta-Biplot and STATIS Dual as multiple textual tables tools
Daniel Caballero-Juliá1, Mª Purificación Galindo Villardón2, Marie-Carmen García3
1 CRESCO Université Toulouse III Paul Sabatier, 118 Route de Narbonne, 31062, Toulouse, Francia. daniel.caballero-julia@univ-tlse3.fr
2 Universidad de Salamanca, Calle Alfonso X El Sabio s/n. 37007 Salamanca, España. pgalindo@usal.es
3 CRESCO Université Toulouse III Paul Sabatier, 118 Route de Narbonne, 31062, Toulouse, Francia. marie-carmen.garcia@univ-tlse3.fr
RESUMEN
El artículo, en primer lugar, expone brevemente los modos de análisis estadístico de datos textuales, así como de análisis cualitativo comúnmente utilizado en ciencias sociales. En un segundo momento, se propone un nuevo tratamiento de los datos con el fin de poder utilizar ambos modos de análisis de forma combinada a la hora de trabajar con múltiples textos de manera simultánea. En el artículo se detalla un procedimiento en el que se utilizan el STATIS Dual y el JK-Meta-Biplot, técnicas multivariantes que representan gráficamente una nube de puntos multidimensional en un espacio de dimensión reducida, para representar la estructura consenso de distintas participaciones a un cuestionario cualitativo. Dicho cuestionario recoge las trayectorias biográficas de profesionales españoles de la Expresión Corporal.
Palabras-clave: Análisis Estadístico de Datos Textuales; JK-Meta-Biplot; STATIS-Dual; Expresión Corporal; cuestionario
ABSTRACT
First, the article briefly shows the manner of statistical analysis of textual data and qualitative analysis that are usually used in social sciences. In a second place, we propose a new treatment of data in order to be able to use both modes of analysis in combination when working with multiple texts simultaneously. The article details the procedure which uses the STATIS Dual and JK-Meta-Biplot analysis, two multivariate techniques graphing a multidimensional cloud of points in low dimension, in order to represent the consensus structure of different entries to a qualitative questionnaire. This questionnaire collects biographical trajectories of Spanish professionals of Corporal Expression.
Keywords: Statistical Analysis of Text; JK-Meta-Biplot ; STATIS Dual ; Corporal Expression ; Questionnaire
1. Introducción
El desarrollo del Análisis Estadístico de Datos Textuales (AEDT) fue posible, a partir de los años sesenta, gracias a la aparición de herramientas informáticas que permitían la aplicación de nuevos algoritmos complejos (Beaudouin, 2016).
En un primer momento abordaremos la Expresión Corporal (EC), disciplina relativamente reciente y muy variada ligada a las actividades artísticas (danza, teatro, mímica…), a partir de un corpus textual procedente de un cuestionario de respuestas abiertas. Acto seguido, explicaremos cómo analizarlo de forma automática, tras realizar una breve exposición de los métodos estadísticos multivariantes empleados tradicionalmente en AEDT, incorporando la utilización del JK-Meta Biplot (Vicente et al., 2001) y el STATIS Dual (Escoufier, 1985; L'Hermier des Plantes, 1976) teniendo en cuenta el trabajo de codificación cualitativa realizado en una fase previa de análisis cualitativo clásico.
El objetivo principal de este artículo reside entonces en mostrar las posibilidades de estas herramientas a la hora de analizar distintos documentos/discursos de manera conjunta desde la perspectiva del AEDT. Así los objetivos específicos serán: primero, aprovechar la codificación cualitativa del objeto; segundo, aprovechar la capacidad de reducción de la complejidad de las técnicas multivariantes; tercero, obtener una representación gráfica de la estructura consenso de los distintos discursos y cuarto, mostrar las ventajas e inconvenientes de la aplicación de cada técnica multivariante a la hora de obtener dicha estructura.
2. Objeto y método de investigación.
2.1. El análisis cualitativo de las trayectorias biográficas de los profesionales en Expresión Corporal en España
La EC es, en España, una disciplina relativamente reciente (a partir de los 60) desarrollada por múltiples personalidades provenientes de espacios como la danza o el teatro (Ferrari, 2012; Sánchez, 2009) y cuyos dominios de aplicación son diversos (artístico, pedagógico o terapéutico). Nuestra investigación aborda el análisis de las trayectorias de profesionalización en EC en territorio español trabajando con una población compuesta por profesionales españoles de EC.
Con el fin de analizar las trayectorias de dichos profesionales sobre cuatro grandes dimensiones (formación, vida profesional, ocio y vida diaria, con especial insistencia sobre el papel que juega la EC en cada una de ellas), se ha obtenido un material compuesto por el texto procedente de las respuestas a preguntas abiertas a un cuestionario administrado en Google Forms© el cual emula las preguntas realizadas en el transcurso de entrevistas semi-estructuradas. El corpus textual ha sido analizado en diferentes etapas asociando los métodos de análisis cualitativos de las ciencias sociales con el AEDT.
La primera etapa de nuestro análisis reposa sobre la comprensión de los fenómenos y de las representaciones sociales. Está fundamentada en el análisis cualitativo propuesto por Murillo et Mena (2006) y Escobar & Román (2011). Y se trata de extraer las unidades de significación aportadas por los propios actores y analizar su manera de estructurarse en el discurso.
Para tal extracción, hemos procedido a la codificación del texto, procedimiento habitual del análisis cualitativo. Más concretamente utilizamos el sistema de codificación propuesto por Murillo y Mena (2006) y por Escobar y Román (2011), que diferencia entre códigos de “sentido” (unidades de significación) y de “referencia” (objeto/s mencionados por el individuo). Atribuyendo tanto códigos emergentes como códigos previstos a priori a las frases del texto obtenemos 32 códigos de “sentido” y 22 códigos de “referencia”.
2.2. Del análisis cualitativo al análisis estadístico textual: un método de análisis textual combinado
La participación de la escuela francesa de análisis de datos, donde una de las figuras más representativas es Benzècri, ha sido de una importancia crucial para el desarrollo del AEDT (Beaudouin, 2016). Benzécri (1973) postuló los principios del Análisis Factorial de Correspondencias AFC que permitía el análisis de Tablas de Contingencia y sobre todo, ponía el acento en la visualización de las proximidades entre diferentes variables ubicándolas sobre dos o más ejes factoriales. Haciendo así posible la interpretación por parte del investigador, gracias a la proyección de una nube de datos de un espacio multidimensional dentro de un espacio de dos dimensiones, “incluso cuando éste no conoce las sutilezas del método” (Beaudouin, 2016, p. 20).
Siguiendo esta tradición, Lebart, Salem et Bécue (1988, 1994; 2000) han elaborado una “caja de herramientas” de los métodos estadísticos más importantes para en el análisis de datos textuales, incluyéndose entre ellos el AFC (simple y múltiple) y el Análisis de Clasificación Jerárquica Ascendente (CJA). Éste último método ha sido utilizado y criticado, por ejemplo, por Dalud-Vincent (2011) para el análisis de datos procedentes de entrevistas semi-estructuradas utilizadas en estudios sociológicos con el apoyo del software ALCESTE[1]. Martin, Adelé et Reutenauer (2016) más recientemente, han utilizado otros programas tales como Sonal o TXM (Heiden, Magué, & Pincemin, 2010) para el análisis de este tipo de entrevistas.
En línea con los trabajos de Lebart, Osuna (2006) propone como alternativa al AFC la utilización de los métodos Biplots (Gabriel, 1971) que permitía, igualmente, la representación simultánea de los datos fila y columna de una matriz Xnxp proyectando la nube de puntos de un espacio multidimensional en un espacio de dos dimensiones.
2.1. Análisis Biplot de múltiples tablas léxicas
La segunda fase de nuestro proceso de análisis implica la aplicación del AEDT descrito por Caballero, Vicente y Galindo[2] (2014b) donde se utiliza la codificación cualitativa obtenida en la primera fase para crear la matriz de datos (38 en nuestro caso). En cada una de ellas se encuentra todo el contenido textual recogido a través de las preguntas del cuestionario utilizado. Esto implica que cada tabla (que llamaremos Tabla Léxica) es capaz de representar de forma independiente todo el discurso de cada cuestionario así como el análisis cualitativo que previamente se ha realizado sobre el mismo.
La metodología que aquí se propone, aprovecha dicho análisis transformando en variables o columnas de la matriz, los códigos obtenidos en la primera fase. Esto nos permitirá, como veremos, conocer su estructura. Al mismo tiempo, se reconstruye el discurso a partir de la recomposición de las frases más características de cada código cualitativo. Existen diversas propuestas para seleccionar las unidades más significativas (por ejemplo, palabras) así como maneras de representarlas. De entre ellas, cabe destacar la propuesta de Contreras, Arias Masa, Luengo y Casas García (2015) que utiliza la Teoría de los Conceptos Nucleares en asociación con las Redes Asociativas Pathfinder. Nuestra propuesta parte, sin embargo, del interés por obtener el discurso característico de cada código cualitativo. Es por ello que nuestras tablas léxicas disponen en las filas de la matriz cada una de las palabras que han sido utilizadas para responder al cuestionario.
El resultado es una tabla léxica con palabras en las filas que han sido agrupadas dentro de códigos cualitativos, los cuales figuran como variables en las columnas de la matriz. Dado que dicha operación se realiza para cada una de las intervenciones (cuestionarios en nuestro caso, pero aplicables a entrevistas, grupos de discusión, etc.), esta operación tiene, en suma, como resultado la acumulación de múltiples tablas (ver Figura 1).
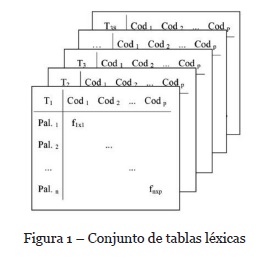
Para reducir el volumen total de palabras y facilitar así el análisis, una vez obtenidas todas las tablas de frecuencias aplicamos el protocolo[3] propuesto por Lebart, Salem et Bécue (2000) de normalización, que previene posibles errores de interpretación debidos a los diferentes modos de escritura; segmentación, que delimita las unidades léxicas que van a ser contabilizadas (palabras, frases…) y lematización, que estandariza y simplifica las expresiones contenidas en las unidades léxicas (verbos al infinitivo, nombres y adjetivos al singular[4], etc.).
Acto seguido, aplicamos a cada tabla Tk el Valor de Caracterización descrito por Caballero (2011, pp. 33-35; Caballero et al., 2014b). Se trata pues de un factor de corrección que además de reducir el volumen de datos a analizar, permite la redistribución de los pesos con el criterio de exclusividad en lugar del de “altas frecuencias”. Responde a la fórmula:

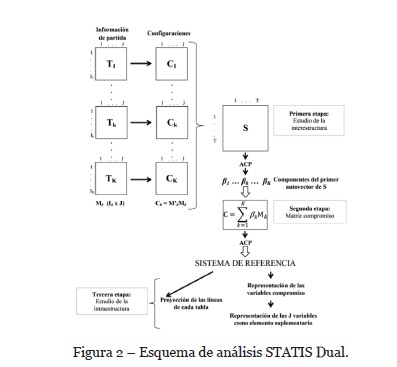

A partir de esta matriz de correlaciones se calculan los valores y vectores propios de la matriz con el Análisis de Componentes Principales (ACP) con el fin de reducir las dimensiones y producir una imagen euclídea donde cada matriz está representada por un punto dentro de este nuevo espacio.
Dentro del espacio estructurado por la distancia Hilber-Schmidt donde cada matriz está representada por un punto y su conexión con el origen del sistema de coordenadas permite la estimación gráfica del coeficiente vectorial entre pares de matrices.
Por otro lado, el análisis Biplot[5] es una técnica de análisis estadístico propuesta por Gabriel (1971) la cual permite la representación gráfica en baja dimensión de cualquier matriz X (n x p) con p variables y n individuos (Gabriel, 1971; Galindo, 1986; Galindo & Cuadras, 1986; Martín, Galindo, & Vicente, 2002). Esta técnica ha sido especialmente desarrollada en el seno del Departamento de Estadística de la Universidad de Salamanca. Hoy en día representa un amplio abanico de posibilidades de análisis multivariante. El Biplot parte siempre de la descomposición en valores singulares:
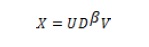

Acto seguido, se calcula la componente común al conjunto de cuestionarios (grupos) en una segunda etapa (ver Figura 3) y se proyecta el conjunto sobre esta nueva componente común.
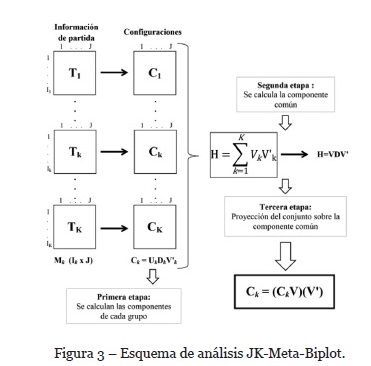
Los resultados gráficos que se obtienen tras realizar los cálculos JK-Meta-Biplot y STATIS Dual se fundamentan en el JK-Biplot y en las correlaciones entre las variables respectivamente. En otras palabras, tendremos a las variables mejor representadas (es decir, nuestro códigos cualitativos)[6]. Todos estos cálculos son realizados de forma automática gracias al software « MultBiplot http://biplot.usal.es» desarrollado por Vicente (2014) en el seno del Departamento de Estadística de la « Universidad de Salamanca ».
3. Resultados
El trabajo de análisis cualitativo que podemos hacer a partir de este gráfico es bastante amplio y depende en gran medida de los objetivos planteados en el inicio de investigación. Aquí mostraremos simplemente la manera de “leer” rápidamente los resultados obtenidos a partir del ejemplo.
En el análisis del STATIS Dual, la proyección euclídea de los objetos es observable en la Figura 4. En ella, cada vector representa un cuestionario y su posición relativa debe ser interpretada como la (di)similaridad entre los diferentes discursos contenidos en cada uno de ellos. Gracias al análisis de la interestructura somos capaces de evaluar la pertinencia del análisis multidimensional de las tablas múltiples y al mismo tiempo nos permite guardar las distancias respecto de los discursos y reagruparlos de una manera más objetiva.
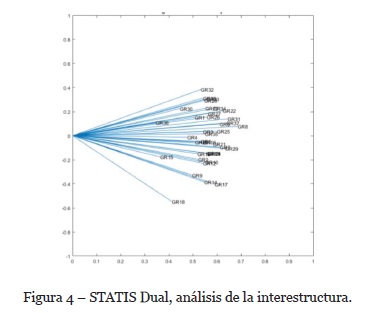
En la Figura 5 observamos la estructura de los códigos que configuran el “discurso compromiso” de los cuestionarios analizados.
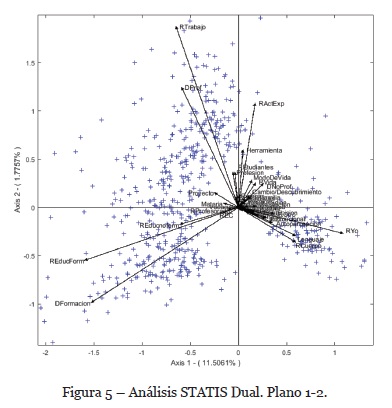
La representación STATIS Dual sitúa los códigos DFormación, REducForm, REducnoform muy próximos entre sí. Tal circunstancia es, cualitativamente hablando, muy coherente. El código DFormación retoma el texto dónde las personas anuncian de forma general sus trayectorias en materia de educación formal e informal. Los códigos REducForm y REducnoform, que precisan el tipo de formación realizada, forman un ángulo “pequeño” con el vector que representa al código DFormación.
Más en detalle vemos que en el 2º cuadrante se encuentran, con una fuerte correlación, los vectores RTrabajo y DProf que retoman las expresiones sobre el trabajo/puesto de empleo y las trayectorias profesionales de los individuos respectivamente. Los vectores RActExp y Herramienta se inclinan hacia el primer cuadrante guardando una cierta similitud con los dos vectores que acabamos de mencionar.
Además, la interpretación del gráfico exige centrarse en el ángulo que forman RTrabajo-REducForm/REducnoform et DProf-DFormación. Un ángulo muy cercano a los 90º que indica al investigador la independencia estadística entre dichas variables. Así, desde un punto de vista cualitativo este fenómeno puede ser interpretado como la presencia de dos discursos completamente diferentes y sin relación aparente entre ellos. Dicho de otro modo, las palabras empleadas dentro de estos códigos son claramente diferentes.
Este fenómeno se repite entre los vectores RActExp y RYo el cual forma un pequeño subgrupo con una fuerte correlación RYo, Lenguaje et RCuerpo. Tal situación es coherente con la lectura de los datos ya que los profesionales participantes hablan de la EC como un medio de comunicación hacia el otro. Se trata ésta de una referencia que encontramos entre los vectores más pequeños, símbolo de la expresión del yo interior.
Los ejes del gráfico pueden, además, ser caracterizados por la presencia/ausencia de uno o más vectores (variables-código) en su proyección al eje, es decir, fijándonos en los cosenos más elevados de los ángulos que forman el eje y los vectores que representan a las variables de la matriz. Así, podemos observar que los vectores representados en el primer y segundo cuadrante caracterizan más fuertemente al segundo eje. En el eje de ordenadas van todos en la misma dirección. No obstante, los vectores del tercer cuadrante se contraponen a aquellos que se encuentran en el cuarto cuadrante. Su correlación es negativa salvo para los códigos Lenguaje-RCuerpo y DFormación cuyo ángulo se aproxima a los 90º. Cuando el ángulo se aproxima a los 180º no hablamos de independencia sino de asociación negativa o de discursos diferentes autoexcluyentes.
Así, en el plano 1-2 tal situación es fácilmente detectable entre el grupo de vectores RTrabajo/DProf y Lenguaje/RCuerpo y RYo y REducnoform/REducForm. Si ampliamos sobre los vectores más pequeños veremos este tipo de ángulo también entre DFormación (3er cuadrante) y DnoProf, datos no profesionales; RVida, referencia a la vida personal del individuo; y ModeDeVida, que retoma las representaciones que tiene el individuo de la EC como modo de vida. No obstante se ha de ser prudente con los vectores que tienen una menor calidad de representación y verificar sus ángulos con otros vectores (teniendo en cuenta la posibilidad de una representación tridimensional o superior)
Para este ejemplo, hemos pedido al programa MultBiplot el cálculo de un tercer eje para poder verificar lo que acabamos de decir. Los resultados pueden observarse en la Figura 6 la cual desvela, tras rotar la proyección de la nube de puntos, una asociación casi nula entre las variables REducForm/REducnoform/DFormación y ModeDeVida /RVida y las otras variables que no estaban representadas en el plano 1-2. Esta nueva representación nos muestra una longitud mayor de las variables Cambio/Descubrimiento (1er cuadrante)y RActExp/RActLud/DNoProf (4º cuadrante). Se aprecia una fuerte asociación entre las referencias a las Actividades expresivas, las referencias a Actividades lúdicas y los Datos no profesionales. Dicho de otro modo, el plano 1-3 expone sobre el eje 3 dos discursos bien diferenciados y fuertemente asociados.
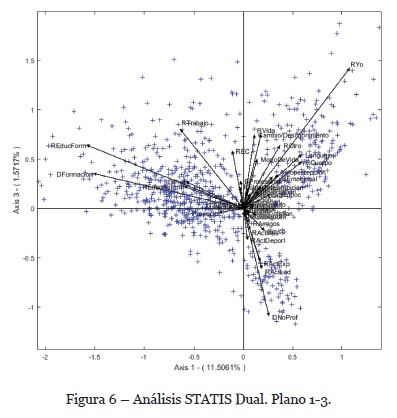
A partir de estas interpretaciones podríamos decir que en los enunciados de las trayectorias educativas la educación formal tiene una presencia primordial. Por otro lado, la presencia de la educación no formal en los profesionales de la EC en España no es nada despreciable. Además, el análisis cualitativo de los textos desvela que los profesionales de la EC en España consideran esta actividad como una herramienta de gran valor, incluso indispensable, para sus actividades profesionales. Así mismo, esta población ha vivido la experiencia de la EC como un descubrimiento/cambio vital que han integrado a su modo de vida.
Si ahora comparamos con el JK-Meta-Biplot, vemos que los resultados numéricos indican que la proyección de la nube de punto media o compromiso realizada por el éste aporta una explicación más eficaz que la aportada por el STATIS Dual habida cuenta de la variabilidad de los códigos utilizados ((27,22% aportada por el JK-Meta-Biplot y 19.67% por el STATIS Dual). La interpretación de los resultados obtenidos por el JK-Meta-Biplot es similar a la realizada con el STATIS Dual. Así, podemos apreciar entonces las diferencias y semejanzas entre la representación gráfica de la Figura 5 que hemos visto y analizado anteriormente y la Figura 7 que se corresponde al plano 1-2 de la solución compromiso del JK-Meta-Biplot. En dicha figura, la separación de las palabras en dos grandes grupos respecto a los valores positivos y negativos del primer eje debe ser subrayada. El aspecto general del gráfico aglutina los marcadores para las palabras entorno a las variables evolucionando a lo largo del eje de ordenadas.
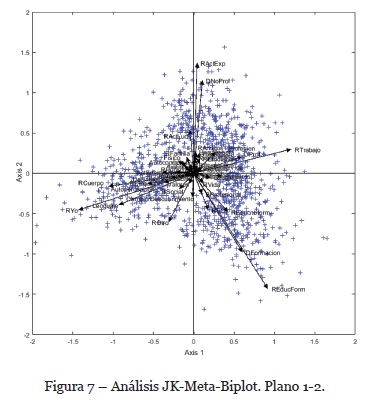
Podemos observar como los vectores de los códigos RActExp, DNoProf y, con una varianza más baja, RActLud tienen una asociación muy fuerte con el eje Y en sus valores positivos. Así pues, podemos interpretar los valores positivos del eje 2 como la dimensión “ocio” del discurso de los profesionales de la EC. Por otro lado, los valores negativos reciben la influencia de los vectores ROtro del 3er cuadrante y REducForm, DFormación, REducnoform, REC muy fuertemente asociados entre ellos, visibles sobre el 4º cuadrante. Por añadidura, estas variables (y en especial las últimas) tienen también una influencia importante sobre el segundo eje formando ángulos cercanos a 45º. En este caso hablamos de variables “de plano”, es decir, aquellas que caracterizan al cuadrante del plano. Sobre el segundo eje, podemos proyectar las variables RYo, RCuerpo y Lenguaje entre un buen número de otros códigos con una longitud mucho menor.
La interpretación sociológica es similar a la ya expuesta por el método del STATIS Dual. La formación de los grupos de variables mejor representados se mantiene en el sentido en que ambos métodos consiguen aportar conclusiones similares. No obstante, el método JK-Meta-Biplot organiza las variables en función de su proyección en todas las dimensiones de la matriz (todos los factores provenientes del cálculo multidimensional) mientras que el método STATIS Dual utiliza únicamente la primera componente. Esta particularidad tiene como consecuencia una distribución ligeramente diferente pero mucho mejor adaptada a los datos.
Aunque, de manera general, los vectores han sido distribuidos de forma simétrica respecto a los resultados obtenidos por el método STATIS Dual, el JK-Meta-Biplot distribuye las variables más limpiamente con ángulos muy cercanos a los 90º. Este ángulo, como ya se ha avanzado, responde a discursos bien diferenciados e independientes. En el ejemplo, se ven cuatro temáticas principales bien diferenciadas: “ocio”, sobre los valores positivos del eje Y donde los profesionales españoles de la EC reflejan su experiencia fuera del trabajo con una fuerte influencia de las actividades expresivas; “Actividad profesional” sobre los valores positivos del eje de abscisas, donde dicha población muestra las trayectorias profesionales que han sido claramente influenciadas por la EC; “Formación” sobre el 4º cuadrante, donde los participantes nos han facilitado sus historias personas en materia de formación; y finalmente “exteriorización del yo” sobre los valores negativos del segundo eje, donde encontramos el discurso sobre EC, entendida ésta como un modo de comunicación/exteriorización del yo a través del cuerpo.
Si continuamos con nuestro análisis, añadiendo un tercer eje, podemos proyectar la nube de puntos compromiso sobre este tercer factor resultante del JK-Meta-Biplot (Figura 8). El método genera los vectores RVida, ModeDeVida, Cambio/descubrimiento, RActExp y Herramienta muy próximos a los valores negativos de este tercer factor. Esto aporta una nueva dimensión a nuestro análisis: la EC como un cambio o descubrimiento que hace cambiar sus vidas hasta el punto de transformarse en “modo de vida” para estos profesionales españoles.
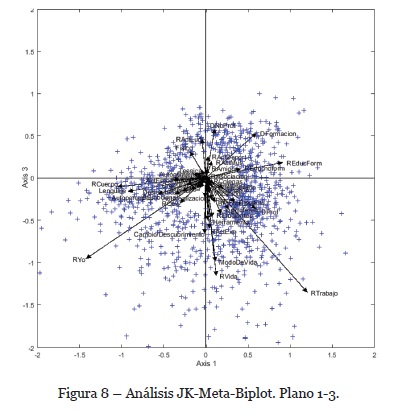
Las variables, RActExp, RActLud et DNoProf que habíamos asociado al segundo eje del resultado JK-Meta-Biplot aparecen muy próximos también al 3er eje. Ante tal caso y dado que observamos una nube de puntos multidimensional que ha sido proyectada sobre sólo tres dimensiones, debemos verificar con las calidades de representación de los códigos la posible atribución a uno u otro plano. Así, rápidamente nos percatamos que DNoProf (56,57% de calidad de representación en el 2º eje y 13,30% sobre el 3º), RActExp (50,24% sobre el 2º y 8,79%) y RActLud (31,19% sobre el 2º y 21,25% sobre el 3º) están mucho mejor representados en el plano 1-2 que en el 1-3. No obstante, RVida, ModeDeVida et Cambio/descubrimiento están bien representadas en el 3º eje con 51,78%, 49,98% y 26,30% respectivamente. Estos resultados nos permiten afirmar que los discursos que caracterizan al tercer eje reposan sobre el “cambio vital” que supone la EC para estos profesionales.
En suma, los factores (ejes) pueden ser caracterizados por las variables que forman entonces un ángulo cuyo coseno se aproxima a 1. Las palabras pueden ser utilizadas para la reconstrucción del discurso presente dentro de cada variable a partir de la proyección perpendicular de cada palabra sobre el vector de la variable que deseamos interpretar.
4. Conclusiones
A la vista de estos resultados, podemos extraer algunas conclusiones importantes según los objetivos que inicialmente se habían planteado:
Objetivo 1: Aprovechar la codificación cualitativa del objeto.
A partir de la lectura crítica, somos capaces de identificar las unidades de significación utilizadas por los actores sociales y generar así una lista de códigos que nos permita analizar objetivamente el texto teniendo en cuenta la subjetividad de los agentes.
El modo de construcción de las tablas léxicas requiere de la aplicación conjunta de la codificación por sentido y por referencia. Esto permite una reconstrucción completa del análisis cualitativo de los textos de una sola pasada; lo que, a su vez, permite no tener que analizar cada tipo de código por separado. Como se ha visto, la frecuencia relativizada de los códigos gracias al Valor de Caracterización nos permite ir, en nuestras interpretaciones, más allá de la simple caracterización por altas frecuencias (Caballero, 2011; Caballero, Vicente, & Galindo, 2014a; Caballero et al., 2014b).
Objetivo 2 y 3: Aprovechar la capacidad de reducción de la complejidad de las técnicas multivariantes y obtener una representación gráfica de la estructura consenso de los distintos discursos.
Los resultados muestran que podemos reconstruir la estructura del discurso a partir de los resultados STATIS Dual y JK-Meta-Biplot. Además, ambos métodos estadísticos pueden ser adaptados a este tipo de datos y de investigación. La gráfica aportada por estos métodos puede ser muy útil para la exposición de los resultados del análisis cualitativo. Ésta permite representar la estructura general del discurso de un colectivo o de un conjunto de texto. No obstante, los resultados obtenidos no son iguales para ambas técnicas.
Objetivo 4: Mostrar las ventajas e inconvenientes de la aplicación de cada técnica multivariante a la hora de obtener dicha estructura.
El método JK-Meta-Biplot aporta una mejor explicación de los datos proyectando la nube de puntos compromiso que es capaz de explicar un porcentaje de la varianza más grande y esto teniendo en cuenta todas las componentes del cálculo multivariante. No obstante, los resultados aportados por los métodos JK-Meta-Biplot y STATIS Dual son satisfactorios en el sentido en que ambas facilitan la comprensión de la estructura interna del (de los) discurso(s) compartido (s) por un cierto número de individuos/textos. Desde un punto de vista matemático, las cifras de absorción de la inercia no parecen muy elevadas (especialmente si se las compara con matrices de datos puramente cuantitativas). La selección de un número más modesto de variables aumentaría dicha absorción, lo que facilitaría a su vez la interpretación de las variables. Sin embargo, como ya ha sido dicho (Caballero, 2011; Caballero et al., 2014b), la aceptación de variables con una baja calidad de representación no supone un problema desde el punto de vista cualitativo.
REFERENCIAS
Beaudouin, V. (2016). Retour aux origines de la statistique textuelle : Benzécri et l'école française d'analyse des données. En 13ème Journées internationales d'Analyse statistique des Données Textuelles (Vol. 3, pp. 17-27).
Benzècri, J. P. (1973). L'Analyse des Donées: L'Analyse des correspondences. Paris: Dunod. [ Links ]
Caballero, D. (2011). El HJ-Biplot como Herramienta en el Análisis de Grupos de Discusión. Salamanca: Repositorio Institucional Gredos de la Universidad de Salamanca. [ Links ]
Caballero, D., Vicente, M. P., & Galindo, M. P. (2014a). Análisis de Grupos de Discusión Basado en HJ-Biplot. En A. P. Costa, L. Paulo Reis, F. Neri de Souza, & R. Luengo (Eds.), III Congreso Ibero Americano en Investigación Cualitativa Vol. 3: Artículos de Ciencias Sociales. Badajoz: Ludomedia.
Caballero, D., Vicente, M. P., & Galindo, M. P. (2014b). Grupos de Discusión y HJ-Biplot: Una Nueva Forma de Análisis Textual. RISTI - Revista Ibérica de Sistemas e Tecnologias de Informaçao, (E2), 19-36. https://doi.org/10.17013/risti.e2.19-35 [ Links ]
Contreras, J. Á., Arias Masa, J., Luengo, R., & Casas García, L. M. (2015). Índices de Nuclearidad (Completo y Reducido), como aportación a la Teoría de Conceptos Nucleares. RISTI - Revista Ibérica de Sistemas e Tecnologias de Informação, (E4), 16-34. https://doi.org/10.17013/risti.e4.16-34 [ Links ]
Dalud-Vincent, M. (2011). Alceste comme outil de traitement d'entretiens semi-directifs : essai et critiques pour un usage en sociologie. Langage et société, 135(1), 9. https://doi.org/10.3917/ls.135.0009 [ Links ]
Escobar, R. M., & Román, H. (2011). Presentation of self in cyberspace: an analysis of self-definitions in blogs and social networks. Revista de Psicología Social. 26(2), 207-222. [ Links ]
Escoufier, Y. (1980). L'analyse conjointes de plusieurs matrices de données. En Jolivet E. (Ed.), Biométrie et Temps (pp. 59-76). [ Links ]
Escoufier, Y. (1985). Objectifs et procédures de l'analyse conjointe de plusieurs tableaux. Statist et Anal des Données, 10(1), 1-10. [ Links ]
Ferrari, H. (2012). Las cuatro Calidades Elementales de Movimiento. Método de Expresión Corporal de Marta Schinca. En G. Sánchez, & J. Coterón (Eds.), Expresión Corporal, Investigación en la práctica (pp. 13-30). Madrid: AFYEC. [ Links ]
Gabriel, K. R. (1971). The biplot graphic display of matrices with application to principal component analysis. Biometrika, 58(3), 453-467. [ Links ]
Galindo, M. P. (1986). An alternative for simultaneous representation: HJ-Biplot. Questiió: Quaderns d'Estadística, Sistemes, Informatica i Investigació Operativa. Barcelona: Universitat Politècnica de Catalunya. [ Links ]
Galindo, M. P., & Cuadras, C. M. (1986). Una extensión del método Biplot y su relación con otras técnicas. Publicaciones de Bioestadística y Biomatemática Universida(17). [ Links ]
Heiden, S., Magué, J.-P., & Pincemin, B. (2010). TXM : Une plateforme logicielle open-source pour la textométrie – conception et développement. En 10th International Conference on the Statistical Analysis of Textual Data - JADT 2010 (pp. 1021-1032).
L'Hermier des Plantes, H. (1976). STATIS : Structuration de tableaux à trois indices de statistique. Montpellier. [ Links ]
Lebart, L., Morineau, A., & Piron, M. (1995). Statistique exploratoire multidimensionnelle. Paris: Dunod. [ Links ]
Lebart, L., & Salem, A. (1988). Analyse statistique des données textuelles. Paris: Dunod. [ Links ]
Lebart, L., & Salem, A. (1994). Statistique Textuelle. Paris: Dunod. [ Links ]
Lebart, L., Salem, A., & Bécue, M. (2000). Analisis Estadistico de Textos. Lleida: Milenio. [ Links ]
Martin, A., Adelé, S., & Reutenauer, C. (2016). Stratégies du voyageur : analyse croisée d'entretiens semi-directifs. En 13ème Journées internationales d'Analyse statistique des Données Textuelles. [ Links ]
Martín, J., Galindo, M. P., & Vicente, J. L. (2002). Comparison and integration of subspaces from a biplot perspective. Journal of Statistical Planning and Inference, 102(2), 411-423. https://doi.org/10.1016/S0378-3758(01)00101-X [ Links ]
Murillo, S., & Mena, L. (2006). Detectives y camaleones, el grupo de discusión : una propuesta de investigación cualitativa. Madrid: Talasa. [ Links ]
Osuna, Z. (2006). Contribuciones al Análisis de Datos Textuales. Salamanca: Universidad de Salamanca. [ Links ]
Pagès, J. P., Escoufier, Y., & Cazes, P. (1976). Opérateurs et analyse de tableaux à plus de deux dimensions. Cahiers du Bureau universitaire de recherche opérationnelle Série Recherche, 25, 61-89. [ Links ]
Reinert, M. (1991). Proposition d'une méthodologie d'analyse des données séquentielles. Bulletin de la Société Française pour l'Etude du Comportement Animal, 1, 53-60. [ Links ]
Reinert, M. (1992). Système Alceste :Une méthodologie d'analyse des données textuelles. En M. Bécue, L. Lebart, & Rajadell, N. (Eds.), JADT 1990 (pp. 144-161). Barcelone: Université Polytechnique de Catalogne. [ Links ]
Sánchez, G. (2009). La Expresión Corporal-Danza en Patricia Stokoe. En Expresión Corporal y Educación. Wanceulen: Editorial Deportiva. [ Links ]
Vicente, J. L. (2014). MULTBIPLOT: A package for Multivariate Analysis using Biplots. Salamanca: Departamento de Estadística. Universidad de Salamanca. [ Links ]
Vicente, J. L., Galindo, M. P., Avila, C., Fernandez, M. J., Martín, J., & Bacala, N. (2001). JK-META-BIPLOT: una alternativa al método STATIS para el estudio espacio temporal de ecosistemas. En Conferencia Internacional de Estadística en Estudios Medioambientales (p. 200). Cádiz: Universidad de Cádiz. [ Links ]
Recebido/Submission: 12/05/2017
Aceitação/Acceptance: 18/08/2017
[1] Resulta interesante acercarse a los trabajos de Reinert (1991, 1992), alumno de Benzècri, que retoman el AFC y CJA en el programa ALCESTE.
[2] Este método de análisis textual propone la conversión del texto procedente de grupos de discusión en tablas de frecuencia corregidas y después analizadas con ayuda del HJ-Biplot (Galindo, 1986).
[3] Para más detales sobre el protocolo consultar (Caballero, 2011; Caballero et al., 2014b; Lebart et al., 2000; Osuna, 2006)
[4] El protocolo propuesto por Lebart et al. Así como por Osuna cambia además, los nombres y los adjetivos al masculino. Nosotros aquí conservamos ambas formas (ej: 1 chico + 1 chica = 2 chico/a).
[5] Agradecemos ampliamente a José Luis Vicente Villardón sus aportes y clarificaciones sobre los cálculos Biplot y Meta Biplot.
[6] El STATIS clásico y el GH-Meta-Biplot operan sobre las filas de la matriz y no sobre las variables.