








Serviços Personalizados
Journal
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO -
 Acessos
Acessos
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkRISTI - Revista Ibérica de Sistemas e Tecnologias de Informação
versão impressa ISSN 1646-9895
RISTI no.17 Porto mar. 2016
https://doi.org/10.17013/risti.17.41-56
ARTÍCULOS
Hacia la Creación de un Repositorio Semántico de Modelos de Contexto Basados en i* y el método DHARMA
Towards the Creation of a Semantic Repository of iStar-Based Context Models and the DHARMA Method
Karina Abad 1, Juan Pablo Carvallo 1, Mauricio Espinoza 1, Víctor Saquicela1
1 Departamento de Ciencias de la Computación, Universidad de Cuenca, 010150, Cuenca, Ecuador. E-mail: karina.abadr@ucuenca.edu.ec, pablo.carvallo@ucuenca.edu.ec, mauricio.espinoza@ucuenca.edu.ec , victor.saquicela@ucuenca.edu.ec
RESUMEN
La definición de Arquitecturas de Software de la mayoría de organizaciones requiere una profunda comprensión de su entorno y estructura organizacional; sin embargo, la construcción de dichos modelos no es una tarea fácil debido a las brechas de conocimiento y comunicación entre los interesados, técnicos y administrativos. El método DHARMA, que hace uso intensivo de la notación i*, propone una solución a este problema, al apoyar la construcción de Modelos de Contexto. En este trabajo se presenta un enfoque para anotación de modelos i* utilizando tecnologías semánticas, para que apoyen la búsqueda y generación de modelos de contexto basados en el conocimiento definido en el modelo ontológico, permitiendo la creación de un Repositorio Semántico de Modelos de Contexto, que será empleado para descubrir relaciones entre diferentes modelos i* y extraer patrones de éstos.
Palabras-clave: Modelos de Contexto; Actores de Contexto; Dependencias estratégicas; Ontología; Repositorio Semántico; Datos Enlazados.
ABSTRACT
The System Architecture definition of the majority of organizations requires a deep understanding about its environment and organizational structure; however, the construction of such models is not an easy task because of the gap of knowledge and communication between the technical and administrative staff. The DHARMA method, which makes intensive use of the i* notation, propose a solution to this problem, supporting the building of context models. This paper presents an approach for annotating the i* models with semantic technologies, to support the search and generation of Context Models based on the knowledge defined in ontological models, allowing the creation of a Semantic Repository of Context Models, which will be used to discover relations between different i* models and extract patterns from them.
Keywords: Context Models; Context Actors; Strategic Dependency, Ontology, Semantic Repository, Linked Data.
1. Introducción
Las empresas modernas se sustentan en Sistemas de Información (SI) diseñados para gestionar la creciente complejidad de las interacciones con su contexto y su operación. La Arquitectura Empresarial (EA – por sus siglas en inglés) (The Open Group, 2009) es un enfoque cada vez más aceptado, el cual abarca varios niveles de diseño arquitectónico, que partiendo de la estrategia de negocio permiten identificar la Arquitectura de SI. Fases tempranas de EA están usualmente orientadas a modelar el contexto empresarial, con el objeto de entender el propósito de las empresas en su contexto (ej., lo que se requiere de ellas) y ayudar a los encargados de la toma de decisiones a diseñar y refinar sus estrategias de negocio, y a los encargados de desarrollar la EA a entender lo que se requiere de los SI resultantes. Lejos de ser una tarea fácil, la construcción de Modelos de Contexto (MC) suele ser compleja, principalmente debido a las brechas de comunicación entre el personal técnico (por ejemplo, consultores internos y externos) con un conocimiento limitado de la estructura de la empresa, las operaciones y la estrategia, y su contraparte administrativa, los cuales imponen presión y limitaciones de tiempo al proceso.
Con el fin de hacer frente a estos problemas, en los últimos años se ha utilizado intensivamente la notación i* para cerrar la brecha entre las partes interesadas (stakeholders), consultores técnicos y no técnicos (Carvallo, 2006), y se ha propuesto el método DHARMA (Carvallo & Franch, 2009), para descubrir arquitecturas empresariales partiendo de la construcción de MC expresados en notación i*.
Adicionalmente en (Carvallo & Franch, 2012) y (Abad, Carvallo, & Peña, 2015), se han propuesto un conjunto de patrones y reglas de instanciación de actores y dependencias, que permiten construir MC de una manera semiautomática. Aunque estas propuestas resultan muy útiles en la práctica, están basadas en técnicas de búsqueda que restringen su aplicación (ej., debido a la dificultad para identificar términos tales como sinónimos y antónimos) y a esto se suman algunos de los riesgos de la ingeniería de requerimientos, como la omisión de requerimientos esenciales y la omisión de requerimientos no funcionales (Jaime Vivas, R., 2012). Para solventar esta dificultad, en este trabajo se propone extender las primeras etapas del método DHARMA con la incorporación de tecnologías semánticas, que permitan mejorar la búsqueda de elementos y la construcción de nuevos MC, basado en un repositorio semántico de MC. Puesto que los modelos i* serán definidos mediante un modelo semántico formal (ontología), esto permitirá mantener un vocabulario común de representación para compartir conocimiento, y usar capacidades de razonamiento que permitan descubrir relaciones que existen entre diferentes modelos, facilitando la reutilización de experiencias a los arquitectos empresariales.
En este artículo se presenta la descripción del proceso de creación del repositorio semántico de MC expresados en notación i*. En la sección 2 se hace una breve introducción de la notación i* y el método DHARMA, se expone el proceso de construcción de MC en la sección 3 y a continuación, en la sección 4, se describe el enfoque utilizado en el proceso de creación del repositorio. Por último, en la sección 5 se presentan las conclusiones y trabajos futuros.
2. Introducción a la Notación i* y el Método DHARMA
En esta sección se presenta una breve introducción a la notación i* y el método DHARMA, se muestra un escenario para la construcción de modelos de contexto mediante el uso de patrones y se presentan trabajos relacionados a esta propuesta.
2.1. La notación i*
El notación i* fue formulado para representar, modelar y razonar acerca de sistemas socio-técnicos. Su lenguaje de modelado está constituido por un conjunto de constructores gráficos que pueden ser usados en dos modelos: el modelo de Dependencias Estratégicas (SD), que permite la representación de actores organizacionales, y el modelo de Razonamiento Estratégico (SR), que representa la lógica al interior de los actores. El presente trabajo hace uso intensivo de modelos SD, por lo que la explicación se enfoca en sus constructores.
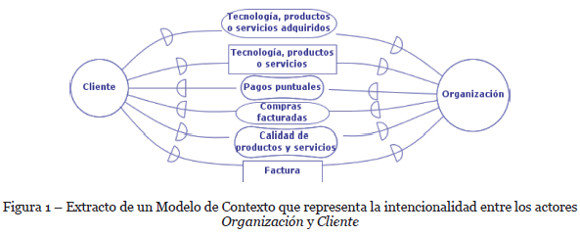
Los actores de los modelos SD son representados por un círculo, estos se pueden relacionar por medio de relaciones is-a (subclasificación) y pueden tener dependencias sociales; una dependencia es una relación entre dos actores, tal que uno de ellos (depender) depende de la realización de alguna intención interna (dependum) de un segundo actor (dependee); la dependencia se caracteriza entonces por un elemento intencional que representa el objeto de la dependencia. Los elementos intencionales primarios son (ver Figura 1): recurso representado por un rectángulo (ej., Factura o Voucher), tarea representada por un hexágono (omitidas en este trabajo por considerarlas demasiado prescriptivas para una etapa de ingeniería de requerimientos temprana), objetivo representado por un óvalo (ej., Compras Facturadas) y objetivo blando representado por un óvalo achatado (ej., Pagos Puntuales); los objetivos representan servicios o requerimientos funcionales, los objetivos blandos representan objetivos que puede ser parcialmente satisfechos o que requieren de un acuerdo adicional acerca de cómo se debe satisfacer y son usualmente introducidos para representar requerimientos no funcionales y de calidad, los recursos por su parte representan elementos físicos o lógicos requeridos para satisfacer un objetivo, mientras que las tareas representan una forma específica de alcanzarlos.
2.2. El Método DHARMA
El Método DHARMA (Discovering Hybrid ARchitectures by Modelling Actors, por sus siglas en inglés) tiene por objetivo definir la Arquitectura Empresarial utilizando la notación i* como herramienta fundamental de modelado; su marco estratégico está basado en el modelo de las fuerzas de mercado y la cadena de valor descritos por Porter (Porter, 1980). El primer modelo (las fuerzas de mercado) está diseñado para analizar la influencia de las cinco fuerzas en el contexto de la organización (amenaza de nuevos entrantes, sustitutos, poder de negociación de los clientes, poder de negociación de los proveedores, y rivalidad entre competidores) y razonar acerca de las potenciales estrategias disponibles para hacerlo rentable. Por otra parte, con el fin de balancear las fuerzas de mercado, las empresas necesitan adoptar una organización interna conocida como Cadena de Valor, la cual engloba las cinco actividades primarias de valor (logística de entrada, operaciones, logística de salida, mercadeo y ventas y soporte) y cuatro actividades de soporte (infraestructura, administración de recursos humanos, desarrollo tecnológico y abastecimiento) requeridas para generar valor y eventualmente un margen (diferencia entre el valor total generado y el costo de realizar las actividades de valor), las actividades primarias son el núcleo y son específicas del negocio mientras que las de soporte son transversales a todas ellas. Aplicando esta teoría, el método DHARMA ha sido aplicado y contrastado en varios casos de estudio a nivel industrial, lo cual ha permitido identificar oportunidades de mejora, algunas de las cuales se presentan en este artículo.
El método DHARMA se estructura en cuatro actividades principales que se explican a continuación.
• Actividad 1: Modelado del contexto y el ámbito de la organización. La organización y su estrategia son estudiados en detalle a fin de identificar el rol que juega en relación a su contexto, este análisis hace evidentes los Actores de Contexto (CA) y las Áreas Organizacionales (OA) que la estructuran, los cuales según DHARMA pueden ser de cuatro tipos (personas, organizaciones, hardware y software). Los CA son identificados en relación a las fuerzas de mercado y analizados en relación a cada OA en la cadena de valor, con el fin de identificar necesidades estratégicas entre ellos (Dependencias de Contexto –CD-); además, las OAs son analizadas entre ellas con el objetivo de identificar sus interacciones estratégicas (Dependencias Internas –ID-). Como resultado, modelos i* SD son construidos y utilizados para soportar el razonamiento y presentar los resultados de esta actividad, varios MC son construidos desde la perspectiva de cada OA, incluyendo sus CA y OAs relacionados, así como sus CD e ID; los modelos resultantes son finalmente combinados en un solo Modelo de Contexto empresarial (Figura 2. Actividad 1).
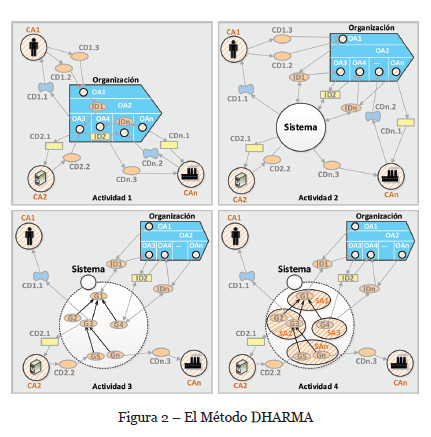
• Actividad 2: Modelado del contexto del SI. Analiza un SI a ser implantado en la organización (puede ser un sistema de información puro o un híbrido que incluya componentes de hardware, software o hardware con software embebido) y el impacto que éste tendría en relación a los elementos incluidos en el MC. Las dependencias estratégicas identificadas en la actividad anterior (internas y de contexto), son analizadas en detalle con el objeto de determinar cuáles pueden ser satisfechas total o parcialmente por el SI, estas dependencias son redirigidas dentro del diagrama i* SD hacia el SI. Este modelo incluye también a la organización como un actor en el entorno del SI, en el cual, sus necesidades son modeladas como dependencias estratégicas sobre el mismo SI (Figura 2. Actividad 2).
• Actividad 3: Descomposición de los objetivos del SI. En esta actividad, las dependencias incluidas en el MC del SI son analizadas y descompuestas en una jerarquía de objetivos que son necesarios para satisfacer las dependencias estratégicas establecidas por los actores en su contexto, estos objetivos representan los servicios que el SI debería proveer para apoyar la interacción con las actividades de los CA y OA. Como resultado, un diagrama i* SR del sistema es construido, usando enlaces medio-fin 1 de tipo objetivo-objetivo (representando una descomposición de objetivos en sub-objetivos) (Figura 2. Actividad 3).
• Actividad 4: Identificación de la arquitectura del SI. Finalmente, los objetivos incluidos en el modelo SR del SI son analizados y sistemáticamente agrupados en Actores del Sistema (SA). Estos objetivos son asociados en grupos de servicios de acuerdo a un análisis de las dependencias estratégicas con el entorno y una exploración del mercado de componentes existentes; las relaciones entre los diferentes SA que forman la arquitectura del SI son descritas de acuerdo a la dirección de los enlaces medio-fin que existen entre los objetivos incluidos dentro de ellos. Los SA resultantes no serán tratados como componentes de software, puesto que éstos representan dominios de software atómicos para los cuales pueden ocurrir varias situaciones: pueden ser componentes de software que cubran la funcionalidad de varios SA, la funcionalidad de un solo SA puede ser cubierta por diferentes componentes de software debido a su ubicación, por ejemplo aplicaciones locales y móviles, o, pueden existir casos para los cuales no exista componentes de software, lo que lleva a la necesidad de software a la medida (Figura 2. Actividad 4).
2.3. Problemas Asociados a la Creación Automática de Modelos de Contexto
A pesar de las guías propuestas en (Carvallo & Franch, 2009), la construcción de MC suele ser realizada de una manera manual y ad-hoc; sin embargo, en (Carvallo & Franch, 2012) y (Abad, Carvallo, & Peña, 2015) se presentan alternativas más sistemáticas que permiten reutilizar elementos de MC (actores y dependencias), contenidos en patrones, estos patrones son usados para apoyar en la construcción de MC i* SD desde cero y eventualmente automatizar este proceso. Concretamente en (Abad, Carvallo, & Peña, 2015) se han identificado varias dimensiones ortogonales útiles para clasificar actores genéricos (a modo de ejemplo ver Tabla 1 en relación al actor genérico Cliente), cada una de estas dimensiones tiene un conjunto de etiquetas de valor asociadas, las que representan potenciales instancias de actores, las etiquetas tienen a su vez asignados conjuntos de dependencias genéricas asociadas. Basado en esta tabla, los profesionales (ingenieros informáticos y personal administrativo) pueden identificar sistemáticamente un gran número de actores en su contexto operacional, seleccionando y combinando las etiquetas de cada dimensión. Para ilustrar el enfoque, se va a considerar las dos primeras etiquetas de tres de las dimensiones de categorización de Clientes incluidas en la Tabla 1, frecuencia/volumen, canal de distribución y forma de pago. En este caso, 12 combinaciones de etiquetas son posibles: Potencial Mayorista a Crédito, Potencial Minorista a Efectivo, Nuevo Mayorista a Crédito, Nuevo Mayorista en Efectivo, Importante Mayorista a Crédito, Importante Mayorista en Efectivo, Potencial Minorista a Crédito, Potencial Minorista en Efectivo, Nuevo Minorista a Crédito, Nuevo Minorista en Efectivo, Importante Minorista a Crédito e Importante Minorista en Efectivo.
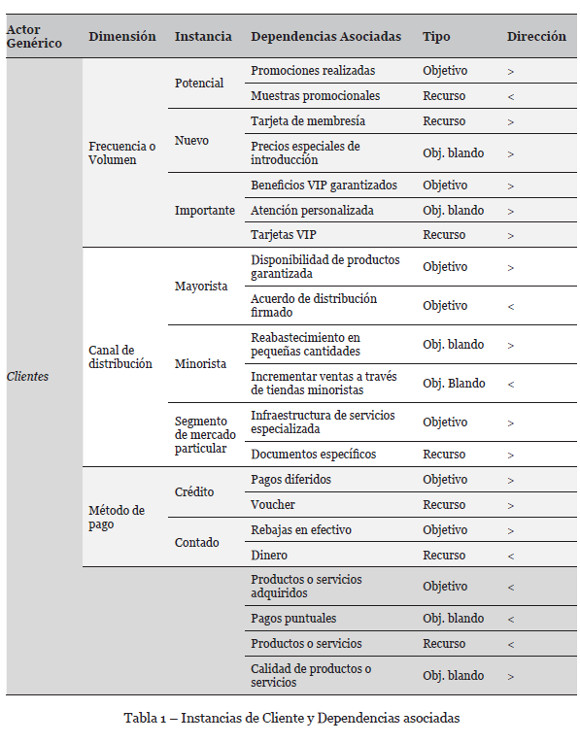
Suponiendo que en un caso particular el Cliente Nuevo Mayorista a Crédito se ha seleccionado de este conjunto de combinaciones, entonces todas las dependencias asociadas a las etiquetas serán las dependencias potenciales a ser incluida en el MC de la organización, de esta manera, la identificación de las dependencias también puede ser automatizada. Si bien esta forma de operar constituye una contribución significativa, tiene el problema que las etiquetas y las dependencias asociadas son “fijas”, lo cual introduce un problema importante desde el punto de vista semántico, al desconocer por ejemplo etiquetas con significado relacionado a las definidas en la tabla. De esta manera, si se elige por ejemplo la palabra “consumidor” en lugar de “cliente”, no se reconocería la etiqueta y por tanto no retornaría potenciales dependencias a ser incluidas en el MC.
2.4. Trabajos Relacionados
El uso de ontologías se ha incrementado en un amplio rango de áreas en los últimos años, esto incluye el uso de modelos semánticos para el modelado de SI. Este trabajo se enfoca en MC obtenidos como resultado del modelado de requerimientos tempranos de acuerdo a las actividades del método DHARMA, se ha realizado un análisis de trabajos relacionados que utilicen ontologías para anotar semánticamente los modelos i*. Del análisis del estado del arte sobre este tema, se ha encontrado y analizado OntoiStar y OntoiStar+ (Najera, Perini & Estrada, 2011) y (Najera, Martínez, Perini & Estrada, 2013), las cuales son meta-ontologías2 usadas para describir modelos i*, con el objeto de integrar diferentes variantes de i*; partiendo de estas ontologías se han desarrollado algunos trabajos relacionados, por ejemplo el desarrollo de TAGOON (Tool for the Automatic Generation of Organizational Ontologies) (Najera, Martínez, Perini & Estrada, 2013); y un método para integrar los constructores variantes de i* mediante el uso de ontologías (Vázquez, Estrada, Martínez, Morandini & Perini, 2013).
En (Beydoun, Low, Gracía-Sanchez, Valencia-García, & Martínez-Béjar, 2014) se propone la anotación de modelos i* utilizando una ontología de recuperación, mediante la cual se verificará la validez del modelo basándose en reglas definidas en la ontología y adicionalmente encuentra ontologías de dominio que permiten extender el vocabulario del modelo anotado.
A pesar de que estos trabajos permiten la anotación de modelos i*, esta propuesta va más allá, buscando la creación de un Repositorio Semántico de Modelos de Contexto, a partir de los cuales un sistema pueda inferir y por ende ayudar a los consultores informáticos a realizar análisis empresariales de una manera más fácil mediante la reutilización e inferencia provista por el repositorio.
Además de las ontologías que describen modelos i*, se ha realizado la búsqueda e implementación de modelos ontológicos relacionados a la organización y su contexto, debido a que se considera necesaria dicha información para cubrir la primera actividad del método DHARMA, y la cual brindará capacidad de vinculación entre dependencias sociales de organizaciones que cuenten con características de entorno y estrategia similares (sectores, industrias, tamaño, etc.). La ontología Job Offer del proyecto NAZOU (Bieliková, Návrat & Rozinajová, 2005) modela conceptos del dominio de ofertas laborales, y está integrada por diferentes ontologías, siendo de interés para este trabajo, además la ontología Classification Ontology, la cual cuenta con una jerarquía completa de clasificación de Industrias y Sectores ha sido incluida en este trabajo.
3. Proceso de Creación del Repositorio Semántico de Modelos de Contexto
En esta sección se describe una propuesta para la creación de un repositorio semántico utilizando los principios de Linked Data (Berners-Lee, 2006) a partir de modelos i* obtenidos como resultado de aplicar las dos primeras actividades del método DHARMA.
El ciclo de publicación de Datos Enlazados comprende una serie de componentes y actividades interrelacionadas (Piedra, N., Chicaiza, J., Quichimbo, P., Saquicela, V., Cadme, E., López, J., Espinoza, M. & Tovar, E., 2015), por lo que esta propuesta está basada en los lineamientos definidos por el Grupo de Trabajo de la W3C (W3C Working Group, 2014), las guías propuestas en (Villazón-Terrazas, 2011). En esta propuesta se distinguen siete fases, las cuales se describen a continuación.
3.1. Preparación de Datos
Los productos de trabajo de cada actividad del Método DHARMA son un conjunto de modelos i*, los cuales pueden ser utilizados como fuentes de datos para suministrar información a un repositorio semántico, en el cual los MC puedan ser representados mediante ontologías. Este trabajo se enfoca principalmente en las dos primeras actividades del Método DHARMA.
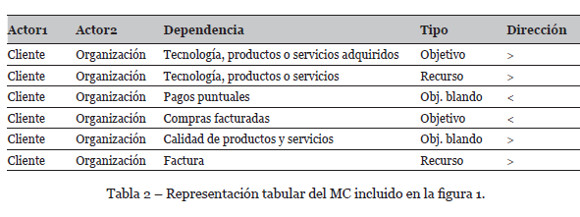
El MC resultante de la primera actividad, puede ser expresado de manera tabular, utilizando una tabla estructurada por los campos (ver Tabla 2): Actor1, Actor2, Dependencia, Tipo y Dirección; donde Actor1 y Actor2 pueden llevar a cabo el rol de Depender o Dependee en base al sentido de la dependencia especificado en el campo Dirección. Por su parte, el campo Dependencia describe la interacción estratégica entre Actor1 y Actor2, y el campo Tipo establece el tipo de dependencia: Objetivo, Objetivo blando, Recurso o Tarea.
La segunda actividad del método busca establecer aquellas dependencias que pueden ser automatizadas mediante un SI. Desde el punto de vista tabular, basta con extender la tabla resultante de la actividad 1, incluyendo un par de columnas donde se establezca si el sistema puede cubrir de manera Parcial o Total los servicios (funcionalidad) requeridos para satisfacer las dependencias.
3.2. Selección de la Fuente de Datos
En esta fase se identifican las fuentes de datos a ser procesadas, en este caso se parte de archivos Excel que representan modelos i* en forma tabular como se mencionó en la sub-sección 3.1. Estos archivos han sido recolectados a lo largo del tiempo en base a experiencias reales en más de 30 empresas a las cuales se aplicó el método DHARMA. En este trabajo se muestra una primera aproximación usada para transformar los datos sin procesar a formato RDF. Además se cuenta con una tabla elaborada por los autores que describe cada una de las organizaciones estudiadas (su nombre, tamaño, sector e industria de acuerdo a la clasificación NACE3) y que servirá como base para enriquecer a la organización y por ende a sus MC.
3.3. Definición de URIs
En esta tercera fase se definen las URIs que representan los recursos de tal forma que permita identificar de manera única a un modelo i*. La definición del formato de la URI está basado en las guías definidas por la comunidad (W3C Working Group, 2012). En la Tabla 3 se muestran las URIs del proyecto y su descripción, mientras que en la Tabla 4 se muestran ejemplos de URIs para cada elemento en el último campo de la Tabla 2.


3.4. Vocabularios
De acuerdo con (W3C Working Group, 2014), los vocabularios estandarizados deberían ser reutilizados tanto como sea posible para facilitar la inclusión y expansión de la Web de Datos. En cuanto a los vocabularios de i*, como se mencionó en la sección 2.4, existen varias propuestas en la literatura de diferentes autores. Para el contexto de la notación i*, se ha seleccionado la meta-ontología OntoiStar como esquema principal para representar modelos i* (SD y SR). Esta meta-ontología permite modelar todos los elementos de i*, tanto nodos (actores y dependencias) como relaciones (is-a, medio-fin, etc). En el contexto de la organización se ha decidido utilizar Job Offer Ontology4, la cual permite describir la organización y su entorno. Para enlazar los vocabularios se ha utilizado la metodología NEON (Suárez-Figueroa et al., 2012), y como resultado se obtuvo la Red de Ontologías DHARMA.
3.5. Generación de RDF a partir de Modelos i*
Existen algunas dificultades en la generación de RDF de modelos i* debido principalmente a la falta de experiencias similares. Actualmente existen varias herramientas que permiten la generación de RDF, sin embargo, una tabla de Excel generada desde un modelo i* no ha sido probado con estas herramientas. Se ha generado un proceso ETL5, el cual a través de un servicio REST permite generar RDF desde un modelo i* expresado en la forma tabular definida en el método DHARMA.
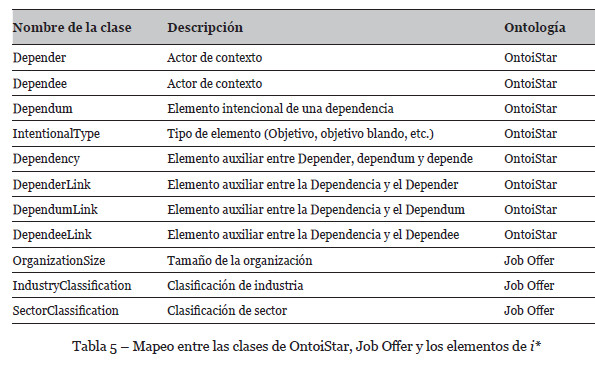
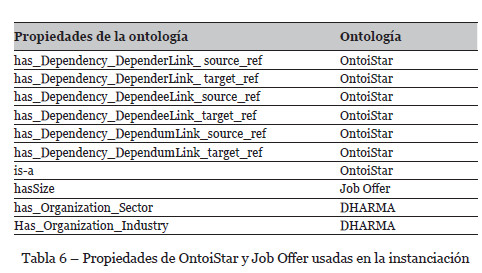
El primer paso para generar RDF es definir un mapeo entre la ontología OntoiStar y los elementos del MC de la Tabla 2, así como un mapeo entre la ontología Job Offer y los elementos de la organización. En la Tabla 5 se muestra el mapeo entre los elementos del MC y las clases de cada ontología. La Tabla 6 muestra las propiedades de las ontologías empleadas en la anotación.
Para la generación de RDF se tomaron los 30 MC, y se instanciaron los distintos elementos de acuerdo a la definición de URIS descrito en la sección 3.3. A continuación se muestra un ejemplo de tripletas RDF resultantes de la anotación de una dependencia i*. En el ejemplo se hace uso de Prefijos por razones de espacio.
Dependencia: Organización depende de Cliente para obtener Pagos puntuales
PREFIX OIS: <http://www.cenidet.edu.mx/OntoiStar.owl#>
PREFIX dharma: <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
INSERT DATA {
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/OrganizacionLink> OIS:has_Dependency_DependerLink_target_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/Organizacion> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/Organizacion> OIS:has_Dependency_DependerLink_source_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependency/ORGANIZACION_PAGOS_PUNTUALES_CLIENTE_1> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/OrganizacionLink> a OIS:DependerLink .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/ClienteLink> OIS:has_Dependency_DependeeLink_source_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependency/ORGANIZACION_PAGOS_PUNTUALES_CLIENTE_1> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/ClienteLink> OIS:has_Dependency_DependeeLink_target_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/Cliente> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/ClienteLink> a OIS:DependeeLink .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependum/Pagos_puntualesLink> OIS:has_Dependency_DependumLink_source_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependency/ORGANIZACION_PAGOS_PUNTUALES_CLIENTE_1> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependum/Pagos_puntualesLink> OIS:has_Dependency_DependumLink_target_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependum/Pagos_puntuales> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependum/Pagos_puntualesLink> a OIS:DependumLink .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependency/ORGANIZACION_PAGOS_PUNTUALES_CLIENTE_1> dharma:has_Dependency_Organization_source_ref <http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Organization/ Organizacion> .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependency/ORGANIZACION_PAGOS_PUNTUALES_CLIENTE_1> a OIS:Dependency .
<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Dependency/ORGANIZACION_PAGOS_PUNTUALES_CLIENTE_1> OIS:Node_sannotation "1" .
}
Este proceso de anotación se realiza para las dependencias de todos los MC y se obtiene como resultado un repositorio semántico de modelos i* en formato OWL, los cuales son publicados en un Triple Store6 para su explotación.
3.6. Enlazando los Datos
Como se mencionó en la revisión de literatura (y hasta donde conocemos) no existe todavía una aproximación de datos enlazados en este contexto; por lo tanto no es posible enlazar los modelos definidos en este trabajo con modelos en otros repositorios.
3.7. Publicación y Explotación
Los datos semánticos generados (RDF) desde modelos i* fueron cargados en una base de datos especializada en semántica, en este caso se utilizó Apache Marmotta7, la cual permite almacenar RDF. Sobre esta base de datos se puede realizar consultas SPARQL8, algo similar a una consulta SQL. A continuación se muestra un ejemplo de consulta SPARQL, la cual obtiene una muestra de Dependums instanciados de acuerdo al actor cliente Cliente.
SELECT distinct ?Dependum WHERE {
?DependerLink OIS:has_Dependency_DependerLink_target_ref ?DependerE .
?DependerLink OIS:has_Dependency_DependerLink_source_ref ?DependencyURI .
?DependeeLink OIS:has_Dependency_DependeeLink_target_ref ?DependeeE .
?DependeeLink OIS:has_Dependency_DependeeLink_source_ref ?DependencyURI .
?DependumLink OIS:has_Dependency_DependumLink_source_ref ?DependencyURI .
?DependumLink OIS:has_Dependency_DependumLink_target_ref ?DependumE .
?DependumE OIS:has_IntentionalElement_IntentionalType ?IntentionalType .
?DependencyURI dharma:has_Dependency_Organization_source_ref ?organization .
?DependencyURI OIS:Node_sannotation ?direction .
?DependerE rdfs:label ?Actor2 .
?DependeeE rdfs:label ?Actor1 .
?DependumE rdfs:label ?Dependum . FILTER(?DependeeE=<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/Cliente> || ?DependerE=<http://www.ucuenca.edu.ec/ontologies/DHARMA.owl#Actor/ Cliente>) .}

4. Conclusiones y Trabajos Futuros
En este trabajo se ha presentado una primera idea de generación de un repositorio semántico de MC basados en i*, siguiendo las mejores prácticas de Linked Data. Basado en los modelos ontológicos seleccionados, se procedió a poblar las ontologías utilizando los datos generados a partir de más de 30 experiencias profesionales sobre diferentes empresas. Los datos fueron cargados en un repositorio semántico, el cual permitió el análisis de los datos a través de consultas SPARQL.
En el futuro se pretende extender el trabajo, iniciando por el desarrollo de una aplicación que permita explotar los datos semánticos generados a través de consultas SPARQL de ejemplo, y además permita extraer patrones similares entre los diferentes modelos i* instanciados dentro del repositorio, basándose en las características del entorno de la aplicación como en las diferentes dependencias creadas. Adicionalmente se pretende extender este trabajo, incluyendo las dos actividades adicionales del método DHARMA, buscando automatizar la inferencia de modelos arquitectónicos de los SI. Estas actividades permitirán descubrir enlaces entre nuestro dataset y la DBPedia mediante el la herramienta Silk, con el fin de compartir la información de los MC y así proveer Datos Enlazados Abiertos (Open Linked Data), que podrán ser accedidos por cualquier persona. Además se planea refinar la ontología DHARMA y enlazarla con ontologías de dominio, esto permitirá enriquecer los modelos i* y crear sistemas de recomendación basados en el conocimiento registrado en el repositorio. También se emplearán ontologías que permitan identificar relaciones lingüísticas como sinonimia, polisemia, homonimia, etc. en las dependencias creadas y evitar redundancia en las recomendaciones de MC que se le puedan hacer a un usuario.
Referencias
Abad, K., Carvallo, J. P., Peña C.: iStar in Practice: On the Identification of Reusable SD Context Models. 8TH International i* Workshop (iStar'15). (2015). [ Links ]
Berners-Lee, T.: Linked Data. http://www.w3.org/DesignIssues/LinkedData.html . (2006). [ Links ]
Beydoun, G., Low, G., Gracía-Sanchez, F., Valencia-García, R., Martínez-Béjar, R.: Identification of Ontologies to Support Information Systems Development. [ Links ]
Bieliková M, Návrat P, Rozinajová V (2005) Methods and Tools for Acquiring and Presenting Information and Knowledge in the Web. In: Proc. of International Conference on Computer Systems and Technologies – CompSysTech' 2005. Varna, Bulgaria [ Links ]
Carvallo, J. P.: Supporting Organizational Induction and Goals Alignment for COTS Components Selection by Means of i*. ICCBSS (2006). [ Links ]
Carvallo, J. P., Franch, X.: Building Strategic Enterprise Context Models with i*: A Pattern-Based Approach. 5TH International i* Workshop (iStar'11), (2012). [ Links ]
Carvallo, J. P., Franch, X.: On the Use of i* for Architecting Hybrid Systems: A Method and an Evaluation Report. PoEM (2009). [ Links ]
Jaime Vivas, R.: Modelamiento semántico con Dinámica de Sistemas en el proceso de desarrollo de software. Revista Ibérica de Sistemas y Tecnologías de la Información, N° 10, pp 19-33. (2012). [ Links ]
Najera, K., Martinez, A., Perini, A., Estrada, H.: An Ontology-Based Methodology for Integrating i* Variants. Proceedings of the 6TH International iStar Workshop (iStar 2013). (2013). [ Links ]
Najera, K., Martinez, A., Perini, A., Estrada, H.: Supporting i* Model Integration Through an Ontology-Based Approach. 5TH International i* Workshop (iStar'11), 43—48, (2011). [ Links ]
Piedra, N., Chicaiza, J., Quichimbo, P., Saquicela, V., Cadme, E., López, J., Espinoza, M. & Tovar, E.: Marco de Trabajo para la Integración de Recursos Digitales Basado en un Enfoque de Web Semántica. Revista Ibérica de Sistemas y Tecnologías de la Información, N° E3, pp 55-70. (2015). [ Links ]
Porter, M.: Competitive Strategy. Free Press. New York, United States (1980). [ Links ]
Socorro, R., Simón, A., Valdés, R., Fernández, F., Rosete, A., Moreno, M., Leyva, E., Pina, J.: Las ontologías en la representación del conocimiento. Instituto Superior Politécnico “José Antonio Echeverría”. (2008) . [ Links ]
Suárez-Figueroa, M.C., Gómez-Perez, A., Motta, E., Gangemmi, A. (Eds.): Ontology Engineering in a Networked World. Springer Berlin Heidelberg. 444pp. (2012). [ Links ]
The Open Group: The Open Group Architecture Framework (TOGAF) version 9. (2009). [ Links ]
Vazquez, B., Estrada, H., Martinez, A., Morandini, M., Perini,A.: Extension and Integration of i* Models with Ontologies. Proceedings of the 6TH International iStar Workshop (iStar 2013). (2013). [ Links ]
Villazón-Terrazas, B.: Best Practices for Publishing Linked Data. (2011). [ Links ]
W3C Working Group: Best Practices for Publishing Linked Data. http://www.w3.org/TR/ld-bp/ . (2014). [ Links ]
W3C Working Group: Best Practices URI Construction. http://www.w3.org/2011/gld/wiki/223_Best_Practices_URI_Construction . (2012). [ Links ]
Yu, E.: Modelling strategic relationships for process reengineering. (1995). [ Links ]
Recebido/Submission: 03/27/2016
Aceitação/Acceptance: 04/14/2016
Notas
1 Enlaces medio-fin: indican una relación entre un extremo y un medio para alcanzarlo (http://istar.rwth-aachen.de/tiki-index.php?page=Means-Ends+Links&structure=i%2A+Guide )
2 Meta-ontologías: Tipo de ontología que especifica las conceptualizaciones que subyacen a los formalismos de representación del conocimiento. (Socorro, Simón, Valdés, Fernández, Moreno, Leyva & Pina, 2008)
3 Nomenclatura estadística de actividades económicas de la Comunidad Europea
4 http://nazou.fiit.stuba.sk/nazou/ontologies/v0.6.17/offer-job
5 Extracción, Transformación y Carga, es el proceso que permite mover datos desde múltiples fuentes, reformatearlos, limpiarlos, y cargarlos en otra base de datos para analizar o apoyar un proceso de negocio.
6 Triple Store: Base de datos especialmente diseñada para el almacenamiento y consulta de tripletas.
7 Apache Marmotta: http://marmotta.apache.org/
8 SPARQL: Lenguaje de consulta para RDF. http://www.w3.org/TR/rdf-sparql-query/